Posty otagowane: korpusy tekstowe
Infrastruktura cyfrowa dla literaturoznawstwa w ramach projektu Dariah.lab
Poprzedni fragment Model cyfryzacji procesu badawczego został wykorzystany w pracach IBL PAN w ramach projektu Dariah.lab, którego zadaniem było stworzenie solidnych podstaw infrastrukturalnych literaturoznawczej infrastruktury badawczej. Celem prac było rozpoznanie cyfrowych potrzeb badawczych [..]Narzędzia i serwisy do analizy tekstu
Jednym z serwisów umożliwiających opracowanie, a następnie analizę materiału tekstowego jest LEM (Literacki Eksplorator Maszynowy) (Maryl, Piasecki, i Walkowiak 2018). Jest to serwis opracowany z myślą o przetwarzaniu tekstów literackich w języku polskim, przede wszystkim [..]Opracowanie tekstu
Pierwszym etapem opracowania tekstu jest jego segmentacja, czyli podział na jednostki – zależnie od tego, jaki jest cel segmentacji, mogą być to tokeny, zdania, chunki etc. Każdy tekst korpusu może zostać podzielony na tokeny, to znaczy najmniejsze wydzielane jednostki znaczące. [..]Tworzenie korpusów
Pierwszym etapem analizy jest stworzenie korpusu językowego lub korpusu tekstowego. Jest to pojęcie z zakresu językoznawstwa korpusowego. Najprościej mówiąc, korpus tekstowy jest po prostu zbiorem tekstów spełniających określone kryteria (Lewandowska-Tomaszczyk 2005). Zależnie od potrzeb [..]Czym jest NLP
Poprzedni fragment Przetwarzanie Języka Naturalnego (Natural Language Processing, NLP) to szerokie określenie, obejmujące wszelkie działania związane z cyfrowymi badaniami nad tekstem. Obejmuje zarówno tworzenie tekstów (wypowiedzeń), przetwarzanie tekstów i korpusów, w tym analizowaniem [..]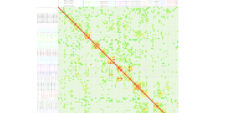
Narzędzia (WebSty, Stylo)
Do analizy stylometrycznej wykorzystać można serwis WebSty (Eder, Piasecki, i Walkowiak 2017; Piasecki, Walkowiak, i Eder 2018). Działa on w oparciu o kilka komponentów, dzięki którym tworzy listę cech poszczególnych tekstów wchodzących w skład badanego korpusu [..]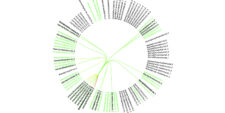
Czym jest stylometria
Poprzedni fragment U podstaw stylometrii, która swoją historię datuje na długo przed powstaniem pierwszych komputerów, leży założenie, że styl – w interesującym nas tutaj przypadku styl literacki, bądź szerzej, styl pisania – może być scharakteryzowany za pomocą policzalnych [..]Plany rozwoju
Stale rozwijająca się baza tekstów polskich z XVI wieku będzie dostarczała kolejnych danych do wykorzystania w Korpusie polszczyzny XVI wieku, co z kolei wpłynie na jakość i kompletność materiałów badawczych. Ponadto w drugim etapie prac korpus zostanie wyposażony [..]Sposoby wykorzystania
Narodowy Korpus Diachroniczny Polszczyzny Idea zamknięcia piśmiennictwa polskiego od najdawniejszych czasów w ramy jednego korpusu narodziła się w środowisku lingwistów po to, by wzorem korpusów współczesnych ułatwić pracę badawczą nad tekstami dawnymi. Projekt Narodowego Korpusu [..]Zastosowane rozwiązania
Istniejący obecnie zalążek korpusu liczy 135 tys. segmentów. Zdeponowano je w bazie danych, a poszczególne rekordy zostały wygenerowane na bazie plików XML utworzonych w specjalnym edytorze pozwalającym na ręczną segmentację i lematyzację tekstu oraz tagowanie poszczególnych [..]Historia powstania
Poprzedni fragment Na fali rozwoju lingwistyki korpusowej skupiającej się zrazu na tekstach współczesnych zaczęły powstawać również polskie korpusy historyczne. W Instytucie Języka Polskiego PAN na przykład powstał (jako jedna z pierwszych inicjatyw tego typu) korpus tekstów staropolskich, [..]Plany rozwoju
Ograniczenie bazy wyłącznie do tekstów znajdujących się w wykazie źródeł podstawowych Słownika polszczyzny XVI wieku od samego początku nie było intencją jej powstania. W założeniu baza aspiruje do możliwie najpełniejszego repozytorium tekstów XVI-wiecznej polszczyzny przygotowanych [..]Sposoby wykorzystania
Dzięki możliwie najwierniejszemu oddaniu typografii tekstu baza może służyć różnym wyrafinowanym zadaniom. Dla zasobu tego zaplanowano konkretne sposoby wykorzystania w ramach platformy spxvi.edu.pl, ponieważ jednak jest ona udostępniana jako zasób otwarty na licencji Creative Commons, przewidywane jest [..]Zastosowane rozwiązania
Baza tekstów dostępna jest jako element serwisu internetowego Słownika polszczyzny XVI wieku. Poszczególne teksty były przygotowywane w specjalnie zaprojektowanym edytorze, zdolnym zapisywać pliki w formacie XML z zastosowaniem wybranego zestawu znaczników TEI opisującego strukturę typograficzną [..]Historia digitalizacji
Sporządzona w latach 50. XX wieku baza materiałowa po latach użytkowania zaczęła coraz bardziej przejawiać objawy zużycia. W najbardziej używanych egzemplarzach archiwalnych papier kruszył się już podczas przekładania stron. Rozważano więc różne metody ratowania tego zasobu, by mógł [..]Wstęp
Portal internetowy Słownika polszczyzny XVI wieku – spxvi.edu.pl – tworzą obecnie trzy główne zasoby – słownik elektroniczny (na który składają się dwie bazy danych – indeks haseł i baza artykułów hasłowych dostępnych z poziomu indeksu), repozytorium tekstów źródłowych oraz zalążek korpusu [..]