
Bogactwo słownictwa i długość zdań
Kolejną oczywistą cechą i przekładu, i — przede wszystkim — opartej na skrótach i uproszczeniach adaptacji dla młodych czytelników jest spodziewane zmniejszenie bogactwa słownictwa w tej drugiej kategorii. Bogactwo słownictwa (zwane też czasem gęstością leksykalną, choć ten drugi termin używany bywa jeszcze w innym znaczeniu) mierzy się najczęściej i najprościej stosunkiem liczby typów (types), czyli unikatowych elementów słownictwa danego tekstu lub grupy tekstów, do jego ogólnej liczby okazów (tokens), najczęściej określanego właśnie angielską nazwą type-token ratio (TTR). Mówiąc jeszcze prościej, gdy Petroniusz pyta Winicjusza: „A nie grywasz na lutni i nie śpiewasz?”, używa co prawda 8 okazów, ale tylko 7 typów; bogactwo słownictwa tego zdania, mierzone jako TTR, wynosi więc 7/8. Niestety użycie tej prostej proporcji nie nadaje się do porównywania tekstów różnej długości — nawet jeżeli porównuje się przekłady tej samej książki; szczególnie zaś wtedy, gdy na tej podstawie chcemy sądzić, co jest, a co nie jest skrótem czy adaptacją. Jak na ironię, wielu wczesnych badaczy — w tym jeden z ojców statystyki językoznawczej, George Udny Yule — nie zdawało sobie sprawy, jak silnie stosunek type-token zależy od długości badanego tekstu. I sławny współczynnik K Yule’a, i wiele późniejszych
wzorów na bogactwo słownictwa powielało tę wadę, jak pod koniec ubiegłego stulecia wykazali Fiona Tweedie i R. Harald Baayen (1998). W miarę skutecznym lekarstwem na ten problem okazało się dopiero zastosowanie tzw. Moving-Average Type-Token Ratio, czyli wyliczanie średniej ruchomej stosunku liczby unikatowych wyrazów do długości tekstu: TTR liczony jest w każdym tekście dla dużej ilości równych próbek, a ostateczny wynik jest uśredniany. W ten sposób porównanie bogactwa słownictwa jest znacznie bardziej miarodajne (Covington and McFall 2010). Można się też spodziewać, że te adaptacje i skróty, które mają za główny cel ułatwienie młodemu czytelnikowi kontaktu z tekstem, uproszczeń mogą również szukać w strukturze zdania — przede wszystkim w operowaniu krótszymi jednostkami syntaktycznymi. Zbadanie, czy tak jest naprawdę, wbrew pozorom nie jest zadaniem trywialnym, chodzi bowiem o ustalenie rozkładu tych wartości i oszacowanie istotności statystycznej ewentualnych różnic. Procedury te wykonano za pomocą wspomnianego już pakietu środowiska programowania statystycznego R.
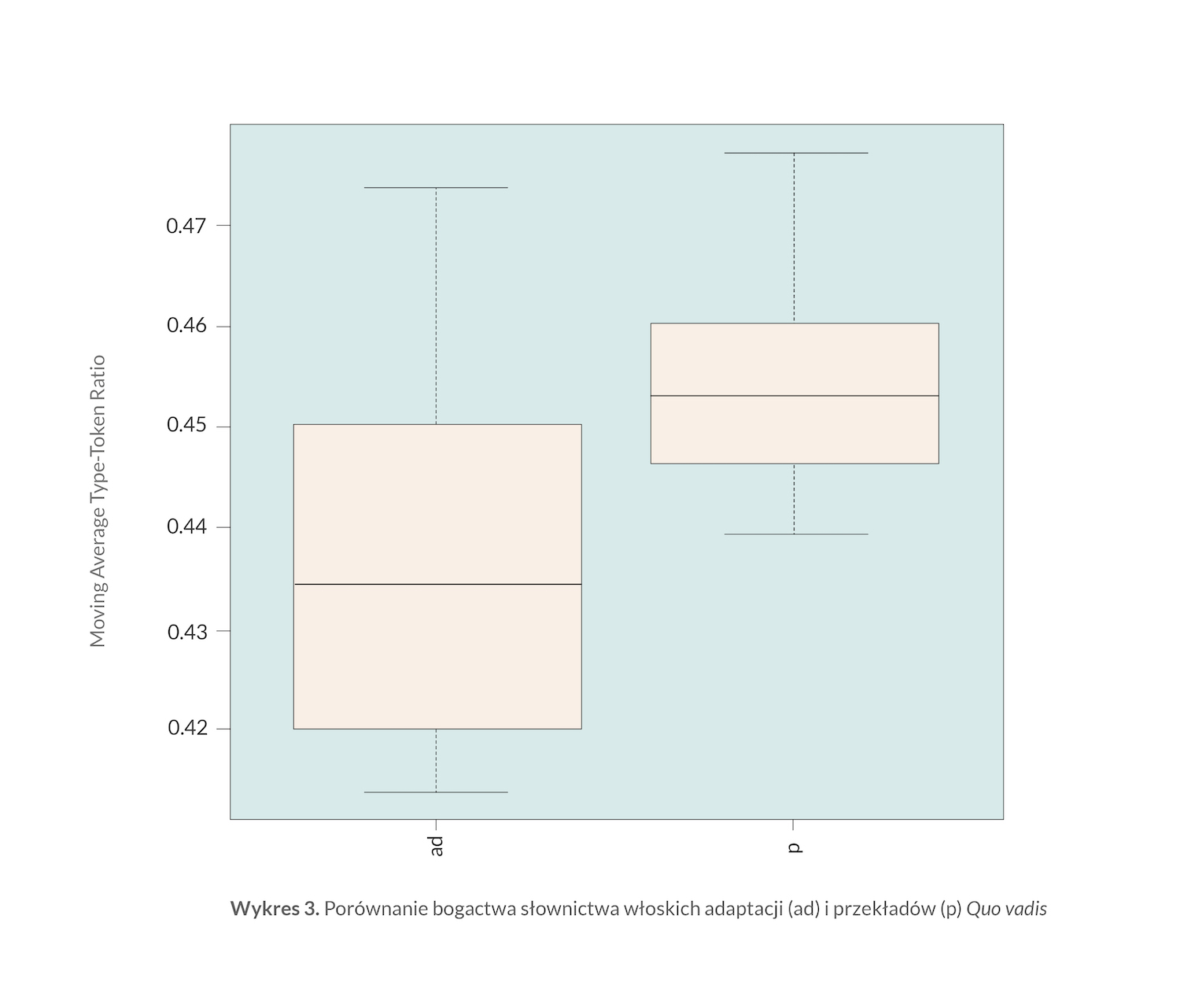
Zastosowanie średniej ważonej stosunku type-token miało przede wszystkim sprawdzić hipotezę o uproszczonym słownictwie adaptacji dla dzieci i młodzieży — a może i ułatwić klasyfikację przypadków granicznych. Po dostosowaniu parametrów analizy do najkrótszego z tekstów i pogrupowaniu tekstów w dwie różne grupy (adaptacji i przekładów) okazało się, że — jak widać na wykresie 3 — różnica między adaptacjami a przekładami jest istotna statystycznie: wartość p (prawdopodobieństwo trafności tzw. hipotezy zerowej, że różnica ta jest przypadkowa) w teście Wilcoxona wynosiła zaledwie nieco ponad 0.00001. A skoro prawdopodobieństwo, że efekt ten jest przypadkowy, jest tak nikłe, należy przyjąć tzw. hipotezę alternatywną, że bogactwo słownictwa jest bardzo istotnie wyższe w „pełnych” przekładach niż w adaptacjach. Zresztą nawet gołym okiem widać, że mediana MTTR (oznaczona czarną, poziomą linią wewnątrz obu „pudełek” wykresu) jest wyższa w przekładach niż w adaptacjach; że zakres najczęstszych wartości, zawierających się wewnątrz „pudełek”, oraz wartości ekstremalnych, oznaczonych „wąsami” wykresu, jest znacząco wyższy w przypadku przekładów. Natomiast adaptacje wykazują znacznie większy rozrzut wartości bogactwa słownictwa.
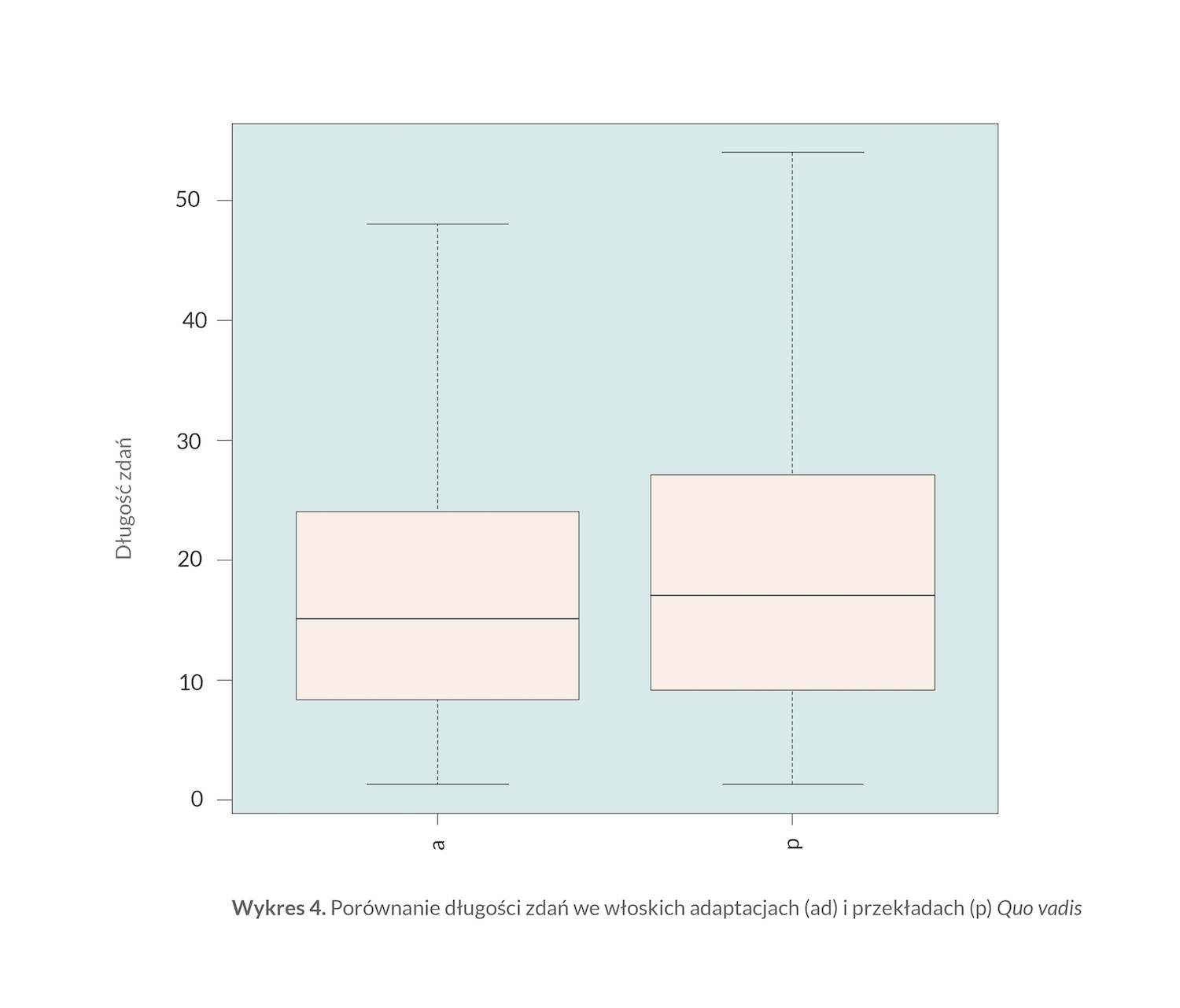
Równie typowa dla adaptacji dla młodego czytelnika powinna być długość zdań — skrócona w porównaniu nie tyle nawet z oryginałem (języki rządzą się swoimi prawami również pod względem literacko akceptowalnej liczby słów w zdaniu), ile z „pełnymi” przekładami. To z kolei sprawdza wykres 4, i znów: mimo wielkiego rozrzutu wartości różnica między skrótami i przekładami pełnego Quo vadis jest istotna statystycznie, choć rozkład wartości nie jest już tak zróżnicowany jak w przypadku bogactwa słownictwa.
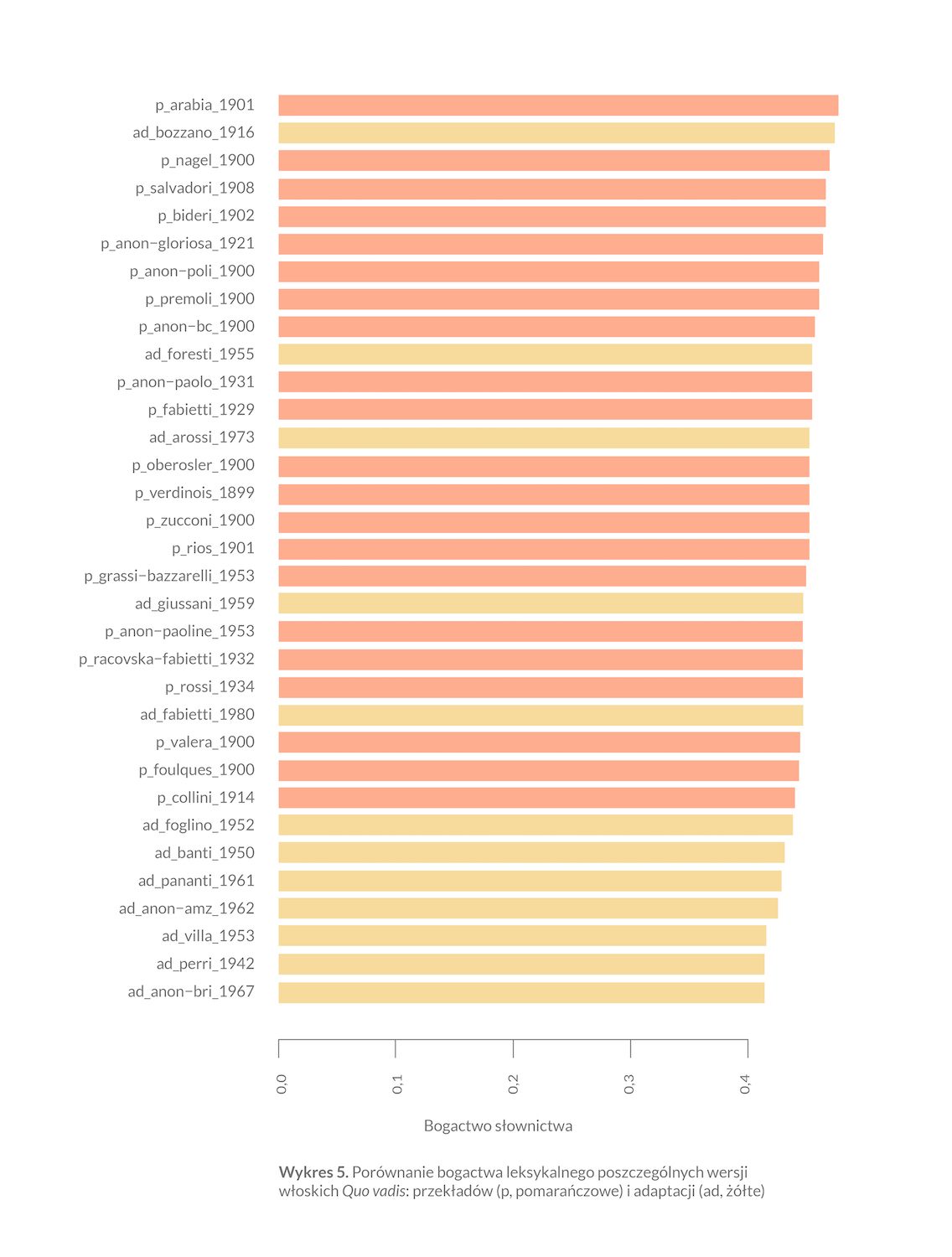
Zjawisko uboższego słownictwa w tekstach samookreślających się jako adaptacje czy skróty jest wyraźne, choć nie dotyczy ono wszystkich przeróbek (wykres 5). W górnej części wykresu — a więc wśród najwyższych wartości bogactwa słownictwa — znalazła się tylko jedna adaptacja, która nie była jednak adresowana do młodzieży. Stosunkowo wysokie wartości MTTR wykazują wersje Pina Forestiego z 1955 roku, nowsza o cztery lata riduzione Maria Giussaniego i dwa najnowsze teksty w korpusie: wersja Anity Rossi (1973) i Ettore Fabiettiego (1980). Trudno jednak nie zauważyć, że siedem ostatnich miejsc zajęły adaptacje młodzieżowe. Znów problematyczna okazuje się klasyfikacja wersji Clary Collini. Jednak jeden z najwyższych wyników bogactwa słownictwa uzyskała ocenzurowana wersja Salvadoriego. Potwierdza to wnioski wyciągnięte na podstawie lektury jakościowej jego tekstu: przysposobienie sienkiewiczowskiego opisu starożytnego Rzymu polega tu nie na uproszczeniu języka powieści, lecz przede wszystkim na ocenzurowaniu go z pobudek obyczajowych.