
Stylo: Wielowymiarowa analiza częstości najczęstszych słów
WCopyFind i Tracer „czytają” tekst w sposób „ludzki” — przynajmniej o tyle, że traktują go jako liniowy ciąg słów i fraz, czyli zupełnie albo prawie zupełnie tak, jak postępuje czytelnik porównujący dwa przekłady tego samego dzieła. Natomiast w ostatniej z zastosowanych metod badań ilościowych — analizie wielowymiarowej częstości słownictwa — nie ma żadnego znaczenia, czy dotyczy tekstów będących przekładem czy przeróbką tego samego dzieła. Włoskie Quo vadis zostaną potraktowane jako całkowicie odrębne i niezwiązane teksty, a ich podobieństwo będzie oceniane wyłącznie na podstawie frekwencji najczęstszych słów. Właściwie jedyną szczególną cechą badania przeprowadzonego na tak licznych przekładach/adaptacjach jednej powieści jest to, że w odróżnieniu od analizy różnych i rzeczywiście niepowiązanych narracyjnie tekstów na liście słów, których częstości będą stanowiły dane dla obliczeń — jak już wspomniano, zdominowanej przez słowa funkcyjne — znajdą się niektóre imiona postaci. Warto o tym pamiętać, gdy dojdzie do porównania uzyskanych tą drogą wyników z rezultatami opisanymi w poprzednich częściach rozdziału.
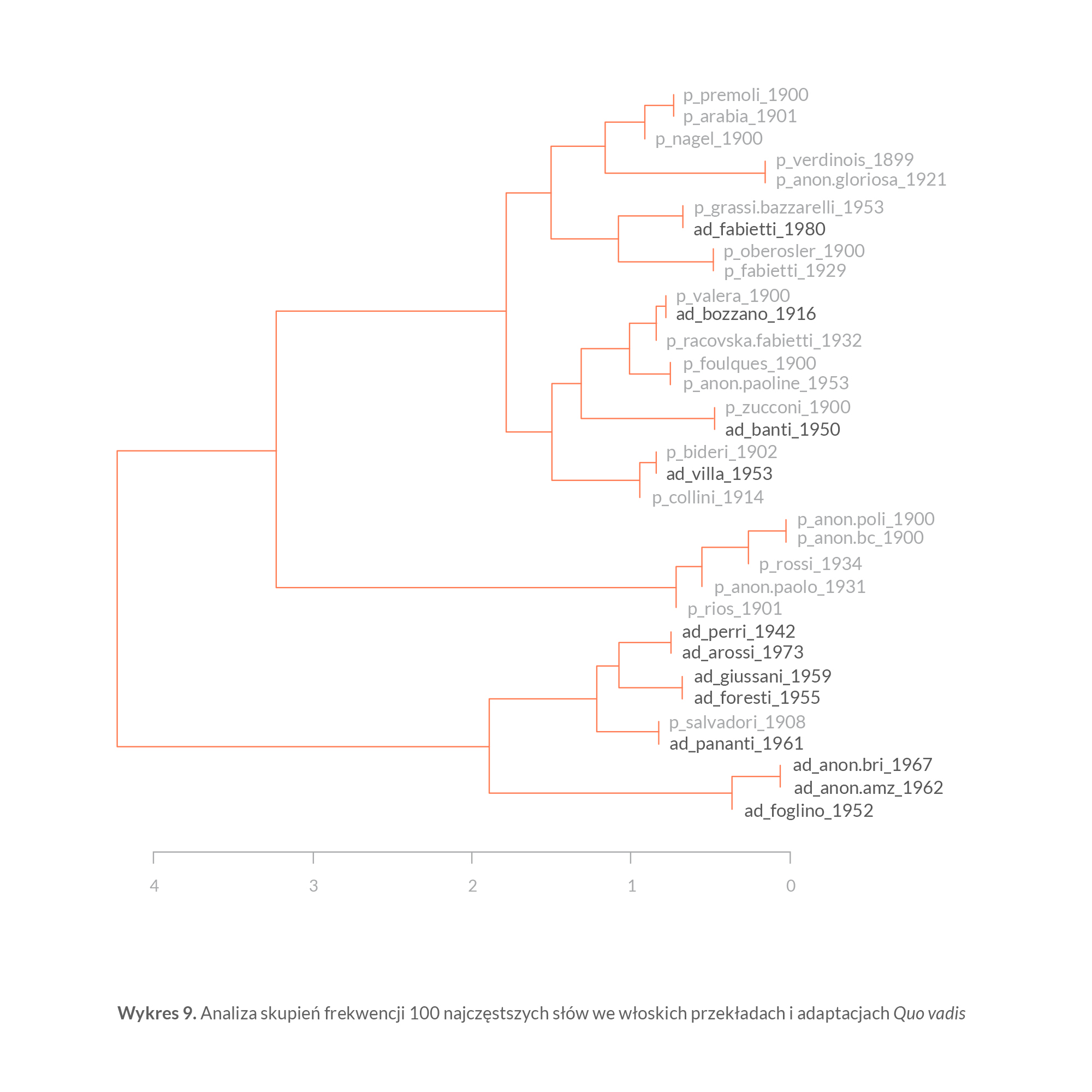
Wykres 9 to tzw. diagram drzewkowy analizy skupień; „drzewkowy” dlatego, że poszczególne teksty zdają się wyrastać ze swoich indywidualnych „gałązek”; „skupień” dlatego, że te gałązki skupiają się w grupy w zależności od stopnia podobieństwa między nimi. Im większe podobieństwo między dwoma tekstami, tym bliżej ich „gałązki” rosną na drzewku; teksty na dwóch najbliższych gałązkach są do siebie najbardziej podobne — bardziej niż do innych tekstów. Z tego powodu analizę tego typu nazywa się czasem analizą najbliższego sąsiedztwa (nearest-neighbour analysis).
 Wykres 9 — wykonany dla 100 najczęstszych słów — dzieli korpus włoskich wersji Quo vadis na dwie główne grupy. Pierwsza z nich to 8 z 11 adaptacji należących do korpusu. Regułę osobnego „sygnału stylometrycznego” zdaje się potwierdzać wyjątek tekstu Salvadoriego, który już wcześniej został uznany za przypadek graniczny. Z kolei do drugiej części wykresu, w której znalazły się wszystkie przekłady, zabłądziły trzy adaptacje. Powinowactwo między pełną wersją Zucconiego z 1900 roku i późniejszym o półwiecze skrótem Rity Banti wykazywały już i WCopyFind, i Tracer; ale obecności w tej części drzewka dwóch innych adaptacji (Bozzano 1916 i Fabietti 1980) nie da się wytłumaczyć równie łatwo.
Wykres 9 — wykonany dla 100 najczęstszych słów — dzieli korpus włoskich wersji Quo vadis na dwie główne grupy. Pierwsza z nich to 8 z 11 adaptacji należących do korpusu. Regułę osobnego „sygnału stylometrycznego” zdaje się potwierdzać wyjątek tekstu Salvadoriego, który już wcześniej został uznany za przypadek graniczny. Z kolei do drugiej części wykresu, w której znalazły się wszystkie przekłady, zabłądziły trzy adaptacje. Powinowactwo między pełną wersją Zucconiego z 1900 roku i późniejszym o półwiecze skrótem Rity Banti wykazywały już i WCopyFind, i Tracer; ale obecności w tej części drzewka dwóch innych adaptacji (Bozzano 1916 i Fabietti 1980) nie da się wytłumaczyć równie łatwo.
Poza tym jednak wykres 9 wskazuje na wysokie podobieństwo stylometryczne w tych samych grupach tekstów, które łączyły się już z sobą w badaniach na identycznych ciągach słów. Całkiem odrębnym językiem przemawiają trzy najkrótsze (i najbardziej językowo uproszczone) adaptacje Ottino Foglino i dwa anonimy, które ukazały się we wspomnianych już wcześniej wydawnictwach: AMZ i BRI. Wersja Paola De Rossiego znów wykazuje silne podobieństwo do anonimowych wydań z 1900 roku Società Anonima Editrice „La Poligrafi ca” i Baldini & Castoldi, a także do przekładu Irmy Rios i ocenzurowanej wersji z 1931 roku opublikowanej przez mediolańskie wydawnictwo „La S. Paolo”. Verdinois i plagiat jego przekładu wydany w 1921 roku nakładem mediolańskiej Gloriosy znalazły się oczywiście obok siebie, natomiast bardziej zagadkowe jest bliskie sąsiedztwo przekładu Foulquesa i anonimowego wydania opublikowanego w katolickim wydawnictwie zgromadzenia paulistów (Edizioni Paoline) z 1953 roku, gdyż close reading wykazało, że chodzi o zredagowany wariant wersji Salvadoriego — tej samej, która sprawia tyle problemów klasyfi kacyjnych. Nie jest też jasne, dlaczego adaptacja Francesca Perriego dla dziesięcioletnich dzieci — według poprzednich metod analitycznych konsekwentnie samotna — znalazła się obok późniejszej o trzydzieści lat, adresowanej do młodzieży adaptacji Anity Rossi ani dlaczego nie znalazły się bliżej siebie przekłady Zucconiego, Valery, Premolego i anonimowe Baldini & Castoldi, wykonane za pośrednictwem angielskiego tłumaczenia Jeremiaha Curtina. Wygląda na to, że frekwencje 100 najczęstszych słów działają jako dość skuteczny test tylko na to, czy dany tekst to adaptacja czy przekład.
W tym kontekście warto przyglądnąć się, jakie to słowa. Lwią część stanowią słowa „funkcyjne” i „gramatyczne”, są to przede wszystkim rodzajniki, przyimki i zaimki:
di; e; che; la; il; a; non; un; i; in; si; per; le; ma; gli; una; con; era; è; da; del; come;
o; della; più; lo; se; al; io; dei; ed; mi; sua; aveva; alla; egli; ti; tu; suo; ad; loro; nel;
disse; anche; lui; casa; delle; ora; tutti; nella; perchè; dell’; poi; me; dal; sono; ne;
quando; quel; ai; tutto; te; così; quella; avrebbe; cui; all’; ho; questo; erano; vi; ha;
dalla; rispose; stesso; prima; dopo; solo; suoi; ciò; og ni; ancora; fosse; quale; mia;
sul; nell’[1]
Jednak nie należy zapominać, że w odróżnieniu od „zwykłej” analizy stylometrycznej, która porównuje różne teksty, mamy do czynienia z 33 tekstami opowiadającymi — może trochę w różny sposób — tę samą, osadzoną w starożytnym Rzymie za czasów Nerona historię miłości Ligii i Winicjusza. Nic dziwnego więc, że na liście 100 najczęstszych s łów pojawiają się: Vinicio; Petronio; Licia; Cesare; Nerone; Roma; Chilone; sig nore; Cristiani; Cristo, città, morte; vita. Nie zmienia to jednak faktu, że — z punktu widzenia mechanizmu analizy stylometrycznej opartej na najczęstszych słowach — te elementy listy frekwencyjnej nie są w żaden sposób „uprzywilejowane”; są równie ważne (lub równie mało ważne) jak di czy che.
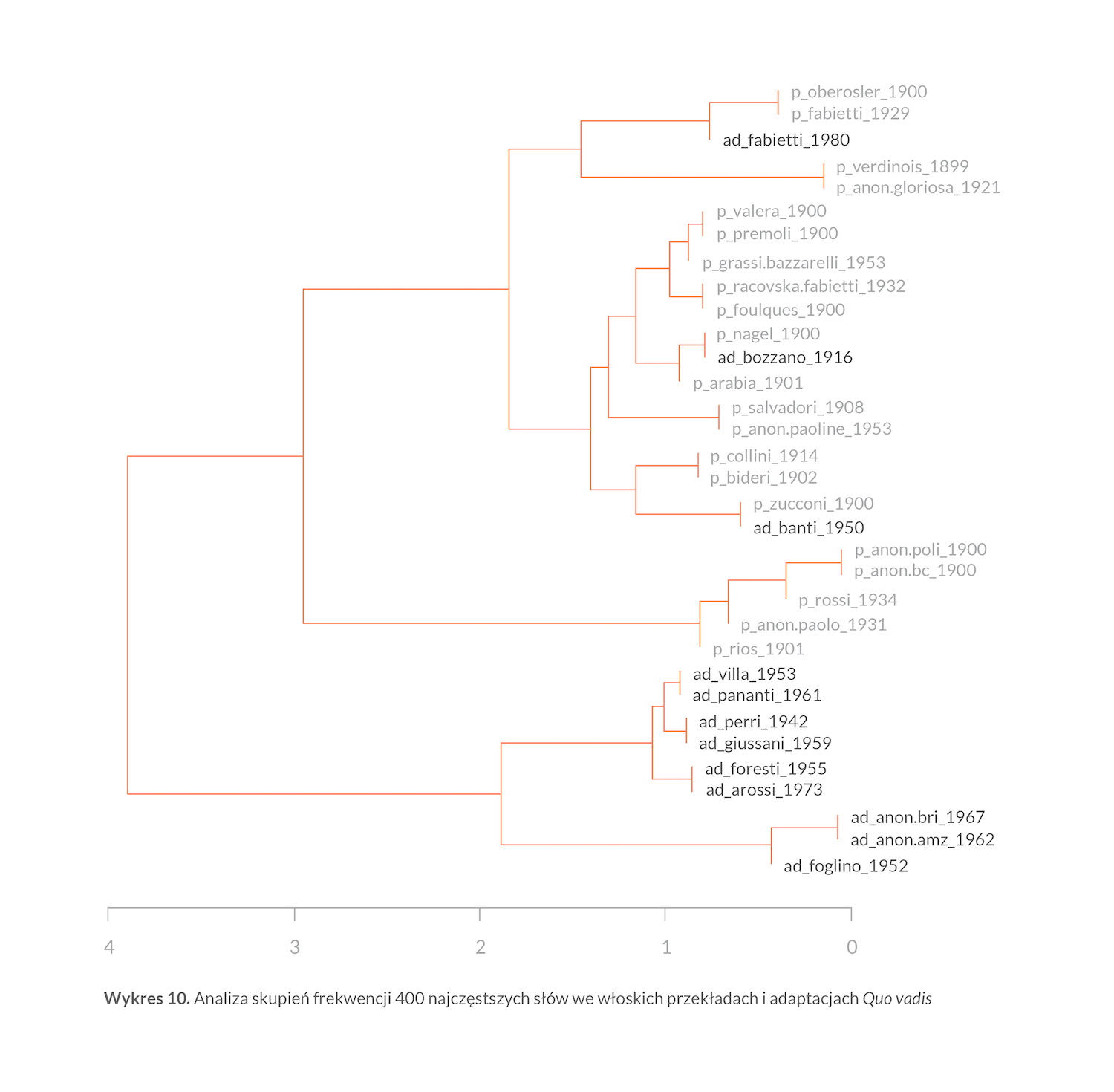
Zwiększanie liczby słów uwzględnionych w badaniu sprawia, że powoli rośnie proporcja słów „znaczących”. Wkrótce pojawiają się postaci drugoplanowe: Ursus jest na miejscu 146., Tigellino — 158. Tuż przed Tygellinem jest Dio; inne ważne abstrakcje (amore; anima; pensiero) znalazły się w drugiej i trzeciej setce. Co to jednak znaczy dla układu tekstów na wykresie analizy skupień? Niewiele: kiedy liczba słów osiąga 400, zmiana jest głównie taka, że wersja Salvadoriego z 1908 tym razem wygląda jak przekład (wykres 10); nie oznacza to jednak doskonałego podziału korpusu na adaptacje i pełne przekłady, bo trzy adaptacje, które poprzednio zawędrowały między wersje pełne, wcale się od nich nie oddaliły. Dalsze zwiększanie liczby najczęstszych słów nie przynosi zmian — jak zwykle, statystyka słów jest już „wysycona”. Potwierdza się to, gdy jeszcze jedno narzędzie dostępne w pakiecie stylo tzw. wykres konsensusowy — łączy wyniki testów dla wielu długości listy słów w jednym przedstawieniu (100, 200, 300, 400, 500, 600, 700, 800, 900 i 1000).
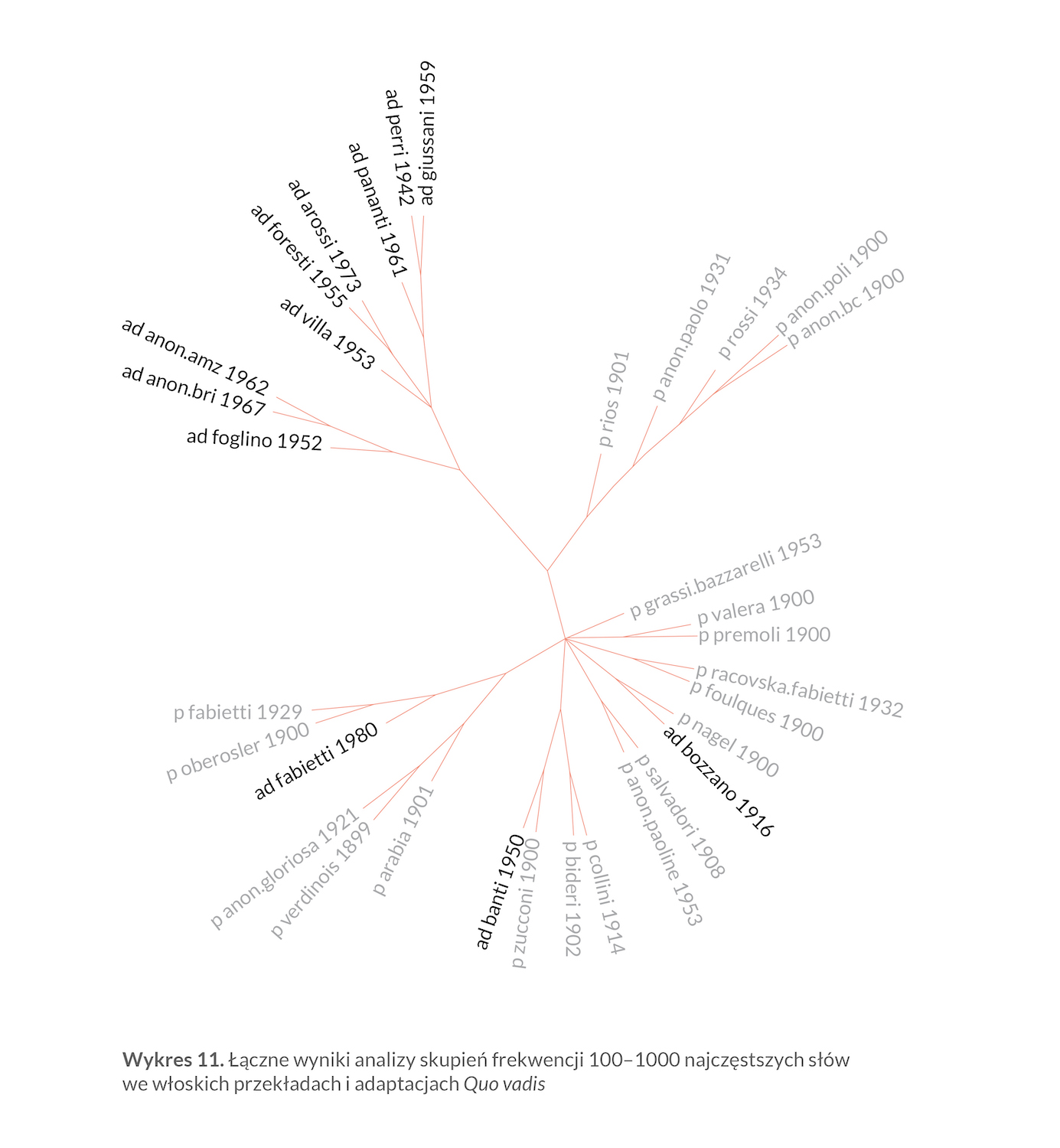 Jak widać, wyniki są bardzo stabilne. Tak szeroki konsensus tworzy dwie odrębne (ale i tak do siebie podobne) grupy adaptacji i kilka innych powiązań, które ujawniały się już w poprzednich badaniach — np. „grupa Baldini & Castoldi”. Z efektów, które nie przetrwały weryfikacji konsensusowej, rzuca się przede wszystkim brak podobieństwa wersji Valery i Bozzano, co potwierdza fakt stwierdzony już w lekturze jakościowej: tekst Valery to przekład z angielskiej wersji Curtina, natomiast wersja Bozzano jest tworem na pograniczu parafrazy i opowieści „na motywach” oryginału.
Jak widać, wyniki są bardzo stabilne. Tak szeroki konsensus tworzy dwie odrębne (ale i tak do siebie podobne) grupy adaptacji i kilka innych powiązań, które ujawniały się już w poprzednich badaniach — np. „grupa Baldini & Castoldi”. Z efektów, które nie przetrwały weryfikacji konsensusowej, rzuca się przede wszystkim brak podobieństwa wersji Valery i Bozzano, co potwierdza fakt stwierdzony już w lekturze jakościowej: tekst Valery to przekład z angielskiej wersji Curtina, natomiast wersja Bozzano jest tworem na pograniczu parafrazy i opowieści „na motywach” oryginału.
Łączne potraktowanie wyników analizy skupień jest bardzo często przydatnym elementem atrybucji autorskiej, ponieważ daje konkretną odpowiedź na pytanie o największe podobieństwa między tekstami. Nie należy jednak zapominać, że — paradoksalnie — znaczna część informacji na temat tego, które teksty łączą się ze sobą pod względem podobieństwa stylometrycznego, zostaje w ten sposób utracona, bo wykres konsensusowy łączy ze sobą tylko te teksty, które sąsiadują w co najmniej połowie cząstkowych pomiarów. W efekcie podobieństwa istniejące, choć mniej wyraźne, nie zostają uwzględnione w konsensusie.
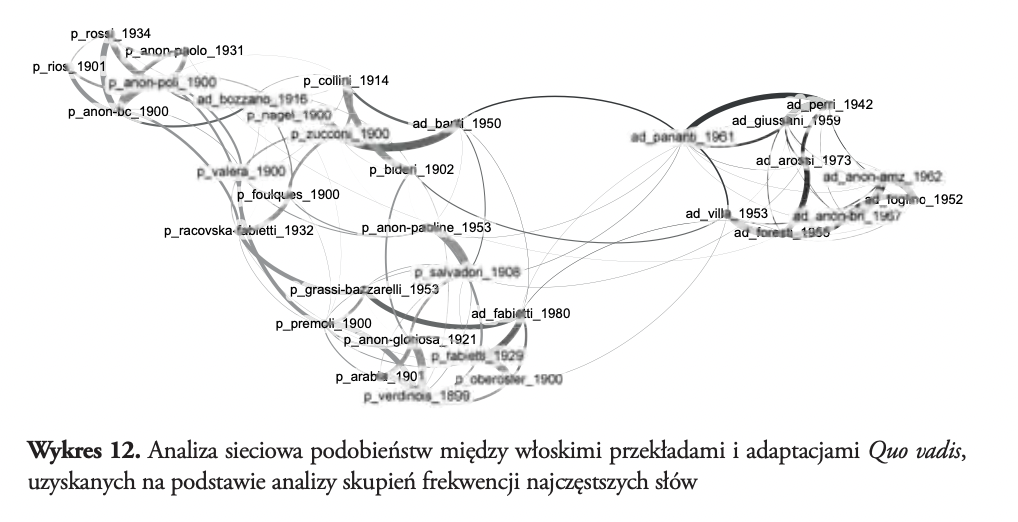
Gdy nie chodzi o identyfikację najbardziej prawdopodobnego autora anonimowego tekstu, a raczej — tak jak w obecnej sytuacji — o distant reading całego układu podobieństw i różnic w większym korpusie tekstowym, warto znów sięgnąć do analizy sieciowej. Ta bowiem, wykazując najsilniejsze związki międzytekstowe — i od siły tych związków uzależniając rozmieszczenie poszczególnych punktów w sieci — uwzględnia również wpływ mniejszych podobieństw i w ten sposób daje pełniejszy obraz istniejących w korpusie zależności.
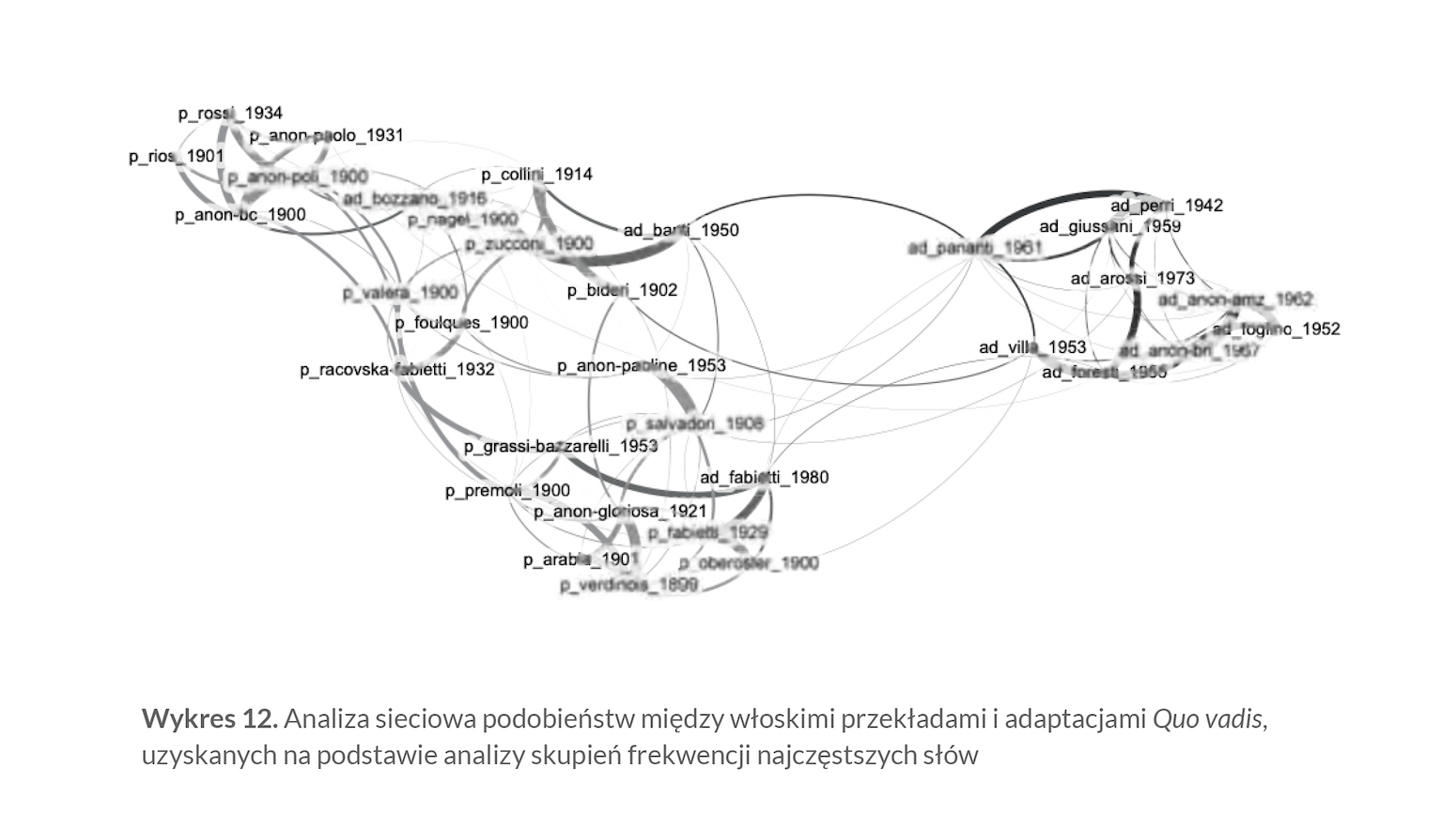
I właśnie dlatego, że analiza sieciowa ukazuje wszystkie, a nie tylko najsilniejsze powiązania między tekstami, wykres 12 jest najważniejszy w niniejszym opracowaniu. Okazuje się, że choć jednostkowe podobieństwa między adaptacjami nie były najsilniejsze, ich połączony wpływ (a na tym właśnie opiera się działanie użytego w network analysis grawitacyjnego algorytmu Force Atlas 2) wystarcza, by pokazać, jak wyraźna jest w rzeczywistości różnica stylometryczna między adaptacjami (najczęściej — adaptacjami dla młodzieży) a przekładami — wystarczy spojrzeć, jak silne podobieństwo łączy większość adaptacji i jak wątłe są ich połączenia z wersjami pełnymi. Z drugiej jednak strony wykres 12 wprowadza pewną subtelną zmianę w tym aspekcie korpusu włoskich Quo vadis: adaptacje Banti (1950) i Fabiettiego (1980), choć konsekwentnie pozostają w sferze wpływów pełnych przekładów, są teraz lekko „przeciągane” w stronę skupiska adaptacji. W przypadku tego drugiego tekstu stylometria oparta na frekwencjach najczęstszych s łów potrafiła silnie powiązać go z wcześniejszym, pełnym przekładem tego samego autorstwa. Natomiast adaptacja Bozzano nie potrafi wyrwać się z grawitacyjnego pola przekładów książki Sienkiewicza. Z kolei bardzo silne powiązanie wersji Salvadoriego i anonimowego wydania paulińskiego z 1953 roku (widoczne w niemal wszystkich badaniach frekwencji s łownictwa) wskazuje, że pomimo przeredagowania późniejszego tekstu, a nawet uzupełnienia go o kilka fragmentów pominiętych wcześniej (co ujawniła lektura jakościowa), stylometria jest w stanie wykryć plagiat w przekładzie.
{kind=link}
Przypisy
- Jest to lista najczęstszych słów pojawiających się we włoskich przekładach Quo vadis. Składa się ona niemal wyłącznie ze s łów funkcyjnych, którym (właśnie dlatego, że są funkcyjne) trudno przypisać konkretne słowa w jakimkolwiek innym języku. W przypadku języka włoskiego i polskiego części tych słów w ogóle nie da się przetłumaczyć z powodu różnic w obu gramatykach. Rodzajniki (takie jak znajdujące się na liście un, una, czy i) we włoskich przekładach nie mają więc żadnych odpowiedników w oryginale; np. włoskie e zastąpiło polskie „i”, „oraz”, z kolei tutti oznacza we włoskich przekładach zarówno: „wszyscy”, jak i „wszystkie”; deklinacje zaimków osobowych także wprowadzają sporą wieloznaczność… Doprawdy na palcach jednej ręki można policzyć te z włoskich słów, które jak più (więcej), quando (kiedy), rispose (odpowiedział/a) czy ancora (jeszcze) są w jakimkolwiek stopniu równoważne z polskimi odpowiednikami. To właśnie brak prostej relacji między listami najczęstszych słów w różnych językach — nawet wtedy, gdy chodzi o relację oryginał–przekład — sprawia, że obserwowane zjawisko silnego sygnału stylometrycznego autora oryginału również w przekładach jest tak tajemnicze i tak interesujące.