

Tracer: Podobieństwo wielopoziomowe
Podobnie jak WCopyFind, który stworzono, by wykrywać plagiaty, i dopiero potem znaleziono dla niego szlachetniejsze zastosowanie, kolejny program użyty w badaniach ilościowych włoskich Quo vadis, Tracer, też miał inne przeznaczenie: badać wszelkie związki intertekstualne między tekstami czy grupami tekstów, stosując bardzo zaawansowane i bardzo liczne (700!) algorytmy porównawcze, biorące pod uwagę cały szereg różnych elementów tekstowych: n-gramy s łowne i literowe wewnątrz i ponad granicami automatycznie wykrywanych zdań przy najróżniejszych wartościach n, z opcjonalnym wykorzystaniem słowników synonimów (Buechler i wsp. 2014). Tracer musi jeszcze udowodnić swoją przydatność w zadaniach, do których został stworzony; natomiast okazał się już bardzo przydatny w porównywaniu przekładów tego samego tekstu, i to właśnie w badaniach nad włoskimi przekładami międzynarodowego bestselleru Sienkiewicza.
Tracer bada bezpośrednie podobieństwo tekstualne w sposób znacznie dokładniejszy — a na pewno intensywniejszy programistycznie — niż omówiony poprzednio program i w odróżnieniu od niego daje odpowiedź bardziej jednoznaczną, a nieodrębną dla każdego zestawu parametrów. Można powiedzieć, że jest to analiza o podwyższonej rozdzielczości — z tym że różnice w wynikach mogą być mniejsze, za to bezpośrednie wskazania istotnego podobieństwa — bardziej wiarygodne, a to dzięki wspomnianemu zastosowaniu bardziej zaawansowanych i liczniejszych algorytmów porównawczych. Właśnie dlatego na szczególną uwagę zasługują wyniki widoczne na wykresie 8, który wykorzystuje opisaną już wyżej analizę sieciową — z tą różnicą, że zamiast prostego procentu fraz identycznych dla danej pary tekstu mamy teraz do czynienia ze wskaźnikiem, który znacznie dokładniej przeczesuje masę tekstową włoskich przekładów Quo vadis.
{kind=link}
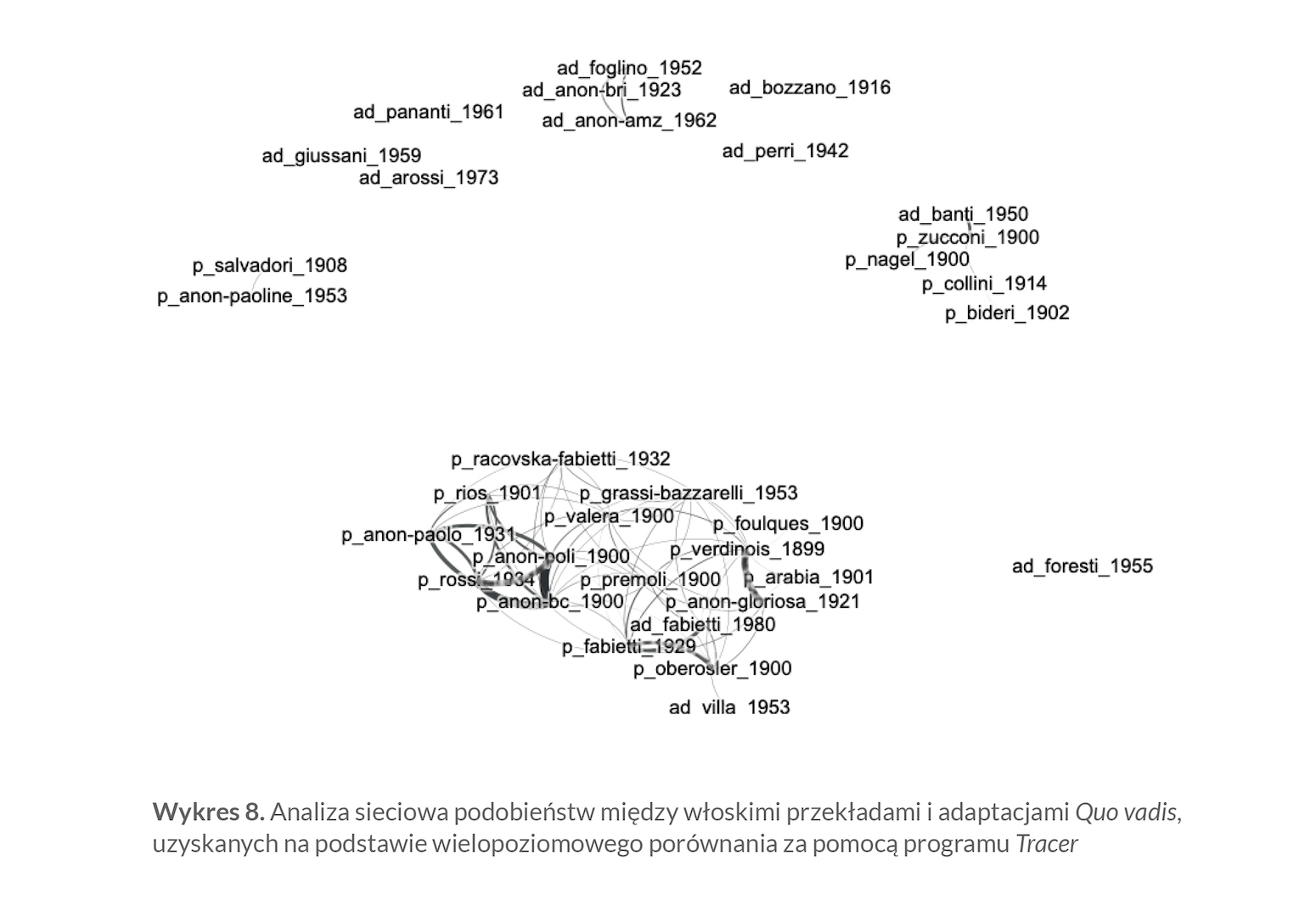
Ponieważ Tracer jest znacznie czulszym narzędziem porównywania tekstów, z wykresu 8 od razu usunięto najmniej znaczące połączenia — w przeciwnym wypadku łączyły się ze sobą wszystkie niemal punkty danych. Podobnie jak na poprzednim wykresie, i tu widać jedno główne skupisko, ale tym razem oprócz „samotnych” tekstów nie brak też większych i mniejszych grupek. Tym, co najwyraźniej odróżnia wyniki z Tracera od tych, które uzyskano w poprzedniej sekcji, jest skład głównej grupy, zdominowanej przez pełne przekłady; adaptacje uchowały się tam tylko dwie: skrót Fabiettiego z 1980 roku — co sugeruje jednak pewne podobieństwo do pełnego przekładu tego samego tłumacza — jak również adaptacja Carla Villi z 1953 roku. Z głównego skupiska zniknęła teraz grupa trzech innych adaptacji (Ottino Foglino i dwa anonimy wydane przez BRI i przez AMZ), by stworzyć osobną grupę. Obserwowane już wcześniej dwie osobne pary: przekładów Bideri-Collini (odpowiednio 1902 i 1914) i przekładu Zucconiego (1900) z adaptacją Rity Banti (1950) łączą się teraz w jedną nieco większą grupę, którą uzupełnia wersja Ketty Nagel, wydana w roku 1900 przez braci Treves w Mediolanie.