
Wcopyfind: proste podobieństwa tekstowe
Trzecim narzędziem porównywania tekstów korpusu było oprogramowanie, które pierwotnie miało służyć innym celom: wykrywaniu plagiatu. WCopyFind, bo o nim mowa, to darmowy i prosty program, który automatycznie porównuje pary tekstów, poszukując identycznych lub prawie identycznych n-gramów s łownych, czyli fraz złożonych z danej liczby (n) wyrazów. Program podaje stopie podobieństwa tekstów w procentach, co pozwala na wizualizację sieciową całego badanego korpusu (Bloomfield 2016).
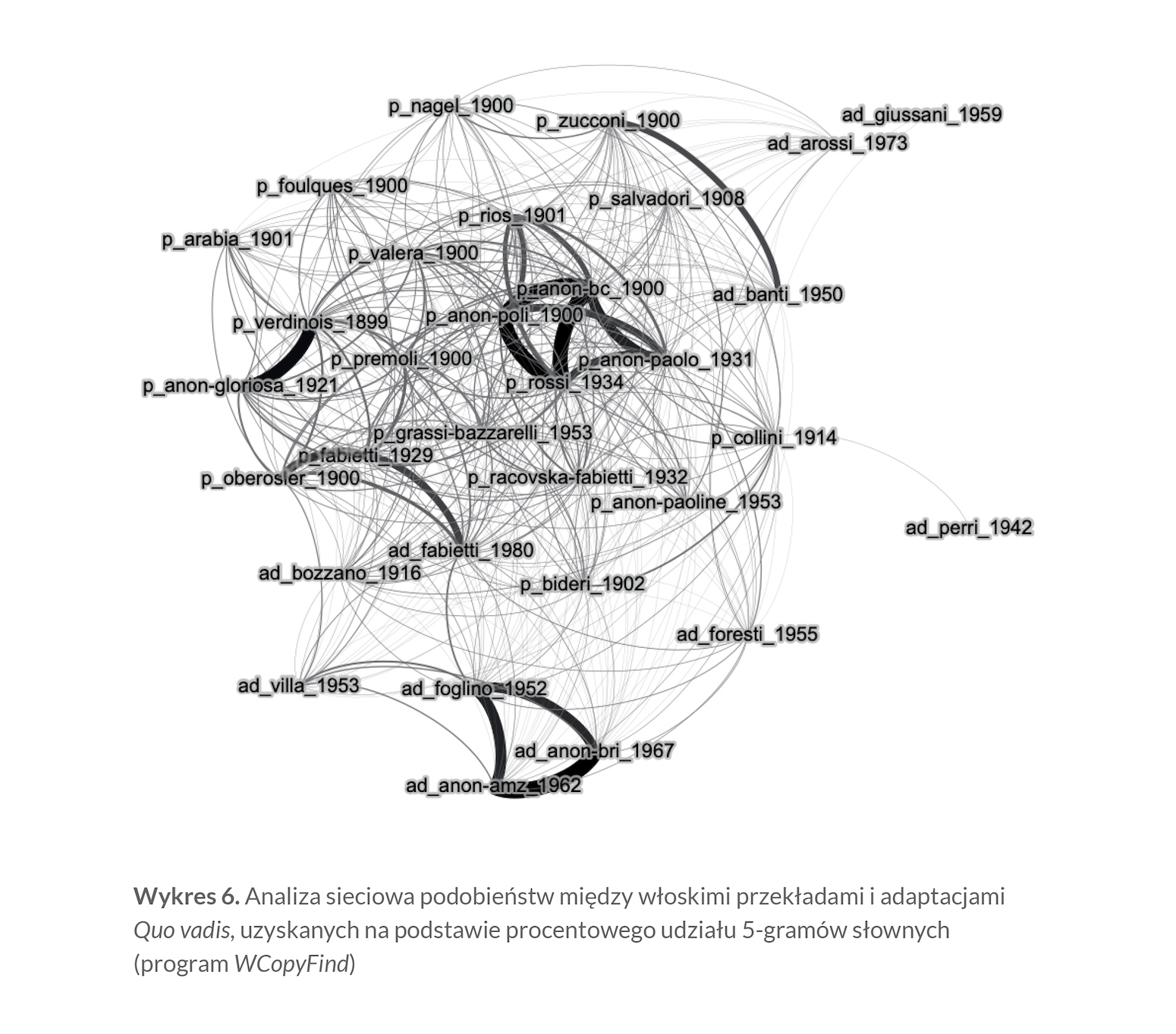
Pierwsza systematyczna próba uporządkowania korpusu włoskich przekładów Quo vadis na podstawie podobieństwa tekstowego wykorzystuje prostą metodę zliczania identycznych ciągów wyrazowych. Dostępne teksty zostały porównane systemem „każdy z każdym”, by uzyskać wskaźnik podobieństwa (w procentach), co można przedstawić w formie tzw. analizy sieciowej. Ta metoda — oficjalnie znana też pod nazwą analizy sieci społecznych (social network analysis), jest ostatnio bardzo popularna w wielu dyscyplinach nauk, i to nie tylko społecznych; posługują się nią fizycy, biolodzy, a ostatnio również humaniści — gdy chodzi o ukazanie związków podobieństwa między elementami zbioru danych. W prezentowanych poniżej badaniach analiza sieciowa jest bardzo prosta: poszczególne elementy (w tym przypadku — włoskie wersje Quo vadis) łączone są w grupy na podstawie podobieństw uzyskanych programem WCopyFind. Teksty wykazują większe podobieństwo, gdy znajdują się bliżej siebie, co z kolei jest wypadkową „wagi” podobieństwa; w tym przypadku chodzi o procent identycznych co najmniej pięciosłownych fraz. Dodatkowym elementem graficznego przedstawienia wyników są linie łączące poszczególne punkty danych: po pierwsze, im większe podobieństwo, tym dwa punkty dzieli mniejsza odległość, a łączy grubsza linia; po drugie, im większe podobieństwo, tym ciemniejszy kolor szarości przedstawionych linii.
Opracowanie bardzo dużego korpusu wymaga skomplikowanych operacji matematycznych; w tym badaniu całość pracy wykonuje program Gephi (Bastian i wsp. 2009) za pomocą grawitacyjnego algorytmu Force Atlas 2. Według jego twórców algorytm „symuluje fizyczny układ w celu umieszczenia sieci na płaszczyźnie. Węzły sieci, czyli punkty reprezentujące poszczególne teksty odpychają się jak tak samo naładowane cząstki, ale krawędzie sieci, czyli miary podobieństwa między węzłami, przyciągają je do siebie jak sprężyny, by w końcu osiągnąć stan stałej równowagi” (Jacomy i wsp. 2014). Prędzej czy później (w zależności od rozmiarów zbioru danych i mocy procesora) taki układ osiąga stan równowagi; sieć czy też „mapa” — tu włoskich przekładów Quo vadis — jest gotowa. Dzięki temu można poszukiwać nie tylko silnych podobieństw (np. świadczących o plagiacie) między parami tekstów, ale — co może ciekawsze — obserwować tworzenie się mniejszych i większych grup. Dodatkową zaletą programu Gephi jest to, że umożliwia „odfiltrowywanie” słabszych powiązań i uzyskanie całej gamy wyników o różnym progu filtracji — to z kolei pozwala oddzielić powinowactwa tekstowe będące efektem plagiatu od podobieństw bardziej subtelnych.
Wykres 6 ukazuje sieć uzyskaną bez użycia filtracji — linie pomiędzy poszczególnymi tekstami pokazują nawet najmniejsze, kilkuprocentowe (czy wręcz jednoprocentowe) podobieństwa. Nic dziwnego, że sieć wydaje się mocno zapętlona i mało czytelna; z drugiej jednak strony dość dobrze przedstawia, jak bardzo podobne muszą być różne przekłady tego samego tekstu, tworzone przez wiele osób w ciągu ponad osiemdziesięciu lat. Być może bardziej zastanawiające jest jednak to, jak wiele wersji nie łączy się nawet w jednym procencie; jak wiele włoskich Quo vadis nie używa nawet jednej, tej samej pięciosłownej frazy.
{kind=link}
Oczywiście nawet w takiej gęstwinie zaczynają pojawiać się silniejsze połączenia. Bardzo silne podobieństwo (ponad 90% wspólnych 5-gramów) łączy przekład Paola De Rossiego, opublikowany przez mediolańską Aurorę, z dwoma anonimami z roku 1900 (Società Anonima Editrice „La Poligrafica” i Baldini & Castoldi). Do tej trójki bardzo podobny jest jeszcze jeden, późniejszy anonim, wydany w roku 1931 przez mediolańskie wydawnictwo „La S. Paolo”, którego właścicielem był Giuseppe Gasparini — tu jednak podobieństwo waha się około 70%. Niedaleko jest też przekład Irmy Rios z 1901 roku, który ukazał się nakładem mediolańskiej Casa Editrice B. Manzoni, ale tu powtarza się tylko co trzecia pięciosłowna fraza.
W dolnej części wykresu 6 pojawia się kolejna trójca, tym razem adaptacji. Rekordowy w całym korpusie jest procent podobieństwa między anonimową adaptacją wydawnictwa BRI z 1967 roku i drugą, także anonimową, wprowadzoną na rynek wydawniczy przez wydawnictwo AMZ w roku 1962. Plagiat jest oczywisty — są one zgodne w 60–80% z wersją autorki trzeciej adaptacji, tej z roku 1952, Liny Ottino Foglino.
Na plagiat wskazuje też zgodność (79%) anonimowego wydania Quo vadis wydawnictwa Gloriosa z Mediolanu (1921) z pionierską wersją Verdinois z 1899 roku.
Co charakterystyczne, ale i zrozumiałe, jak dotąd przekłady łączyły się najchętniej z przekładami, adaptacje — z adaptacjami. W jednym z nielicznych przypadków, w których dzieje się inaczej, podobieństwo rzędu zaledwie 44% między przekładem Ettore Fabiettiego z 1929 roku a sygnowaną tym samym imieniem i nazwiskiem adaptacją wydaną w roku 1980 zdaje się ustalać oczekiwaną wartość dla tego typu pokrewieństw między tekstami; z kolei duże (53%) podobieństwo wersji Fabiettiego do przekładu Giuseppe Oberoslera z 1900 roku pozwala odgadnąć, że to on był jej podstawą i punktem odniesienia.
Na drugim biegunie wartości podobieństw do innych włoskich Quo vadis plasuje się adaptacja Francesca Perriego. Adresowana do bardzo młodych czytelników (dzieci dziesięcioletnich) nie jest podobna do żadnej innej wersji, czy to pełnej, czy skróconej.
Choćby dlatego — i dla większej przejrzystości wyników — warto „odfiltrować” najsłabsze i zapewne przypadkowe podobieństwa. Jak widać na wykresie 7, „odcięcie” tekstów najmniej podobnych do innych usuwa je na zewnętrzne orbity powstałego układu. Ponieważ — jak dotąd — brak wzorcowych ustaleń, jaki tak naprawdę stopień podobieństwa jest przypadkowy, decyzja, by wyeliminować podobieństwa mniejsze niż 10%, była dość arbitralna. Mimo to wynik jest ciekawy, bo poza pojedynczymi tekstami (czy najwyżej parami tekstów) tworzy się rozciągnięty co prawda, ale jednak mniej lub bardziej związany trzon włoskiej tradycji przekładania Quo vadis. Wewnątrz niego można wyróżnić co najmniej trzy zwarte grupy, skupione oczywiście wokół tych, które były już widocznie na poprzednim, „nieodfiltrowanym” wykresie.
{kind=link}
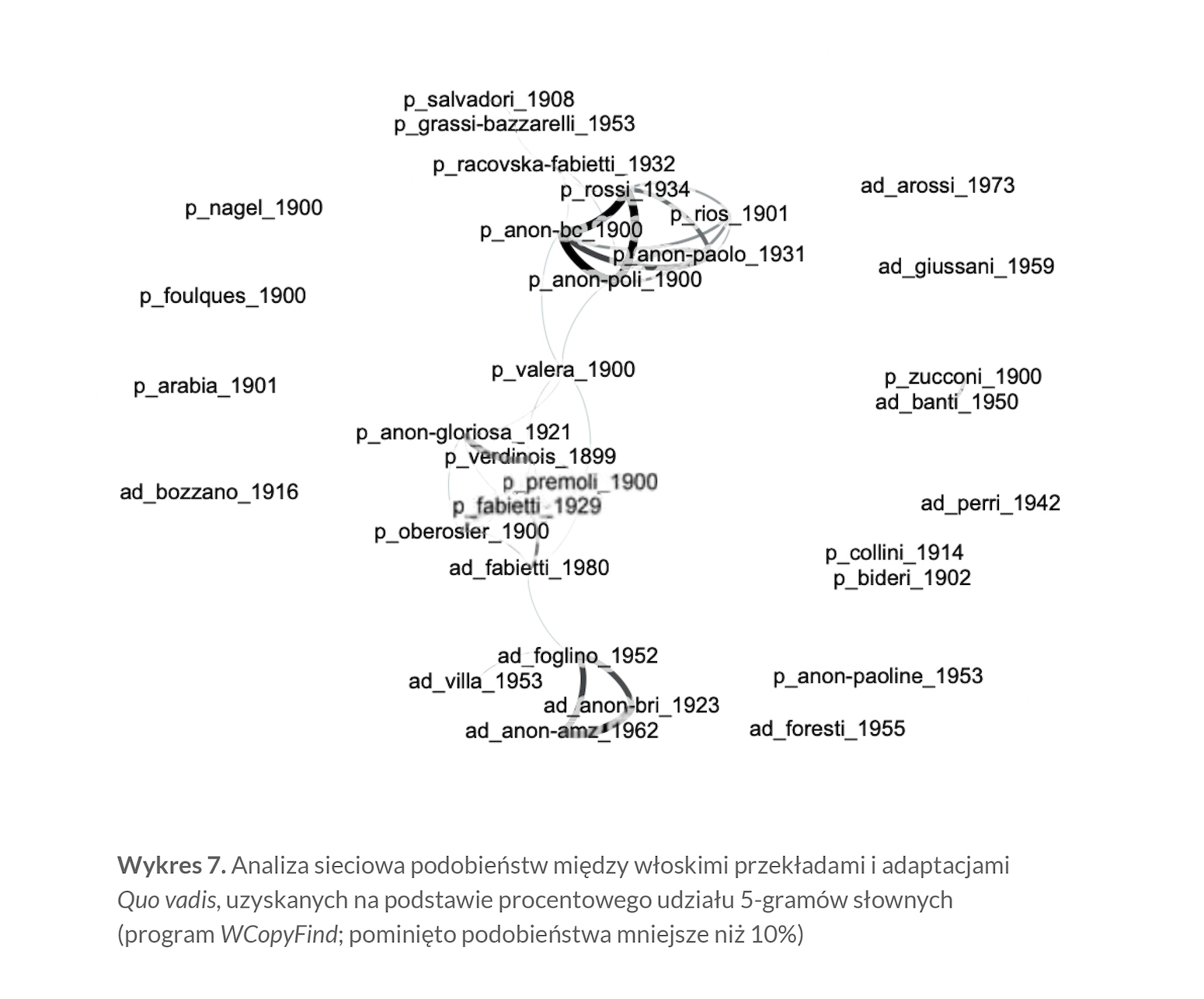
Widać teraz, że ku „grupie Baldini & Castoldi” grawituje nie tylko wersja Irmy Rios, ale również przekład Marii Czubek-Grassi i Eridana Bazzarellego (Mondadori, Mediolan 1953) i ocenzurowana wersja Salvadoriego (1908). Cała ta grupa łączy się — przez niewielkie wspólne podobieństwo do wersji Valery z 1900 roku — z podwójnym systemem, na który składają się Verdinois (1899) z anonimem z Gloriosy (1921) i triada Fabietti (1929 / 1980) — Oberosler (1900). Na uboczu tej konstelacji pojawia się grupa nie trzech, jak przedtem, ale teraz czterech adaptacji, bo powiązana z dwoma anonimami wydawnictw BRI (1967) i AMZ (1962) adaptacja Ottino Foglino łączy się z drugiej strony ze skrótem Carla Villi (Ed. Giacchini, Mediolan 1953).