

Materiały i metody
Ogromny materiał tekstowy, jakim są przekłady i adaptacje rzymskiej powieści Sienkiewicza na język włoski, jest bardzo trudny do usystematyzowania za pomocą tradycyjnych metod literaturo- czy przekładoznawczych. Zadanie to komplikują dodatkowo opisane w poprzednich rozdziałach nieuczciwe praktyki stosowane nagminnie przez włoskich wydawców (plagiaty, parafrazy i przeróbki wcześniejszych tłumaczeń), kłamliwe informacje podawane na stronach tytułowych (np. „tłumaczenie całkowite”, gdy w rzeczywistości chodzi o skrót), a także obecność w obiegu czytelniczym bardzo licznych adaptacji dla dzieci i młodzieży. Nierzadko to samo wydawnictwo w kolejnych publikacjach tego samego przekładu raz podawało nazwisko tłumacza, a innym razem — nie. Z drugiej strony teksty sygnowane nazwiskiem tego samego tłumacza niekoniecznie są identyczne. Wszystko to sprawia, że wspomożenie tradycyjnej analizy jakościowej tekstu analizą ilościową (distant reading) wydaje się w tym przypadku szczególnie pożądane.
Twórcą pojęcia distant reading był włoski (czy może włosko-amerykański) kulturoznawca Franco Moretti, który od końca ubiegłego stulecia „sprzedawał” swoje „makroanalityczne” spojrzenie na literaturę. Najpierw pisał o „geografii” literackiej, zarówno tej w świecie przedstawianym (np. miejsca pochodzenia negatywnych bohaterów w powieściach Dickensa czy miejsca akcji w utworach Balzaca), jak i realnym (trendy wydawnicze w różnych krajach). Już w swej pierwszej wyraźnie „dystansowej” pracy nie ominął zagadnień translatologicznych, bo pisał o drogach dyseminacji przekładów na kontynencie europejskim (1997). Badania literatury metodami ilościowymi, ekstratekstualnymi (bazującymi na danych np. o czasie, miejscu i liczbie wydań) i intratekstualnymi (koncentrującymi się na elementach językowych tekstu) Moretti stosował na Stanford University, gdy wraz z Mattem Jockersem założył Stanford Literary Lab, czyli „laboratorium literaturoznawcze”. Zaowocowało to dalszymi i głośnymi publikacjami, z których jedna doczekała się nawet przekładu polskiego (2016). Jak pisze amerykański kolega Morettiego, makroskopowe traktowanie literatury — oparte nie (tylko) na tekstach, ale i na metadanych, czyli na najróżniejszych informacjach zewnętrznych dla bardzo wielu tekstów, to nowa szansa dla jej historyków, bo może im ułatwić odpowiedzi na liczne pytania o ewolucję stylu w literaturze; o istnienie „narodowych” cech literackich i o ich losy w kontekście literatury powszechnej; o przepływ inspiracji literaturami narodowymi; czy o istnienie (lub nie) kanonów literackich (Jockers 2013: 28).
Warto jednak podkreślić, że stylometria — drugi element metody przyjętej w prezentowanych w tym rozdziale badaniach — jest znacznie starsza od distant reading. Jej początków można dopatrywać się co najmniej pod koniec dziewiętnastego wieku, gdy Wincenty Lutosławski ustalał chronologię dialogów Platona, zliczając wybrane cechy stylistyczne tego działu twórczości greckiego filozofa (1897). Gdy do arsenału stylometrów trafiły komputery, okazało się, że „sygnały” chronologiczne i – jeszcze lepiej — autorskie dokładniej wykrywa się, licząc znacznie łatwiej dostępne (dla komputera) elementy tekstu: zwykłe frekwencje słów, i to słów najmniej „znaczących”, bo „gramatycznych” — tych, które występują najczęściej w każdym języku naturalnym: zaimków, przyimków, czasowników modalnych… Atrybucja autorska tekstów stosuje takie podejście do tekstu przynajmniej od przełomowej pracy Mostellera i Wallace’a, w której w ten właśnie sposób udało się przypisać anonimowe nowojorskie teksty ulotne z czasów kampanii o ratyfikację Konstytucji Stanów Zjednoczonych konkretnym ojcom założycielom (1964). I choć tradycyjnemu literaturoznawcy model języka oparty na bag of words („worku ze słowami”) może wydawać się zupełnie nieodpowiedni w badaniach nad literaturą piękną, liczne badania tekstów literackich wykazują, jak trudno autorowi ukryć własny, bardzo charakterystyczny „odcisk palca” — z tym że tu zamiast z liniami papilarnymi mamy do czynienia z frekwencjami najczęściej używanych w danym języku słów.
Ponieważ z opisanych w tym rozdziale metod właśnie ta wymaga najwięcej wiedzy specjalistycznej, a równocześnie wydaje się najmniej zgodna z intuicją tradycyjnego literaturo- czy przekładoznawcy, warto nieco dokładniej przybliżyć jej założenia i sposób działania.
A założenia są takie: różne elementy językowe — nawet te, które wydają się pozbawione znaczenia w potocznym tego słowa znaczeniu, a więc spójniki, przyimki itp. — stosowane są przez każdego użytkownika w pewien indywidualny sposób. Ich policzenie i porównanie ich częstości metodami analizy wielowymiarowej (bo ciągi częstości np. 100 najczęstszych słów dają od razu 100 wymiarów) pozwala na grupowanie tekstów pod kątem autorstwa. I nie tylko, bo gdy frekwencje takich najczęstszych słów połączą ze sobą teksty indywidualnych autorów, bardzo często — szczególnie przy większych korpusach — pogrupują z kolei tych autorów w większe związki: chronologiczne, rodzajowe, nawet genderowe… Dlaczego? Do końca nie wiadomo. Może dlatego, że te sto najczęstszych słów w każdym języku naturalnym stanowi mniej więcej połowę objętości każdego z tekstów. O ile językoznawcy wiedzą z prawa Zipfa, że w każdym języku naturalnym jest stosunkowo niewiele bardzo częstych słów, a za to wiele bardzo rzadkich, o tyle literaturoznawcom John Burrows musiał już dawno przypomnieć, że „badając [w sposób tradycyjny] dzieła literackie, zachowujemy się tak, jak gdyby jednej trzeciej, dwóch piątych czy nawet połowy materiału po prostu w nich nie było” (Burrows 1987: 1). A tymczasem właśnie tu, w statystyce nie skrzydlatych, tylko na pozór „nieważnych” słów kryje się zapewne tajemnica indywidualnego stylu pojedynczego artysty, epoki, gatunku… Może właśnie dlatego niewidzialne „gołym okiem” różnice między nimi stają się bardzo znaczące, gdy zastosuje się do nich filtr analizy wielowymiarowej. Zwykle już 100 najczęstszych słów w zupełności wystarcza jako papierek lakmusowy atrybucji autorskiej. I choć obowiązuje zasada „im więcej, tym lepiej”, w praktyce statystyka wysyca się — a wyniki stają się bardzo stabilne — na poziomie 1000–2000 słów (Rybicki, Eder 2011; Eder 2015). Warto podkreślić, że analiza frekwencji najczęstszych słów nie poszukuje identycznych czy podobnych kolokacji, lecz zlicza słowa pojedyncze — można powiedzieć: wyrwane z kontekstu.
Szczegółowe wyjaśnienia metodologiczne warto połączyć z opisem działania wykorzystanego przeze mnie pakietu stylo (Eder i wsp. 2016), napisanego dla środowiska oprogramowania statystycznego R Core Team 2017, który stanowił podstawę analizy stylometrycznej w prezentowanych badaniach. Otóż pakiet pobiera wersje elektroniczne wszystkich tekstów badanego korpusu; każdy tekst dzielony jest na pojedyncze słowa; tak tworzy się swoisty leksykon całego zbioru tekstów. Następnie dla każdego ze słów liczy się jego częstość w korpusie, co z kolei pozwala na sporządzenie rangowej listy frekwencyjnej. Do dalszej analizy wybiera się odpowiednią liczbę najczęstszych słów (w badaniach opisanych w tym studium wybrano ich 1000). Następnie częstości tych 1000 słów liczone są w każdym tekście z osobna; w ten sposób każdemu z tekstów odpowiada teraz 1000-elementowy ciąg frekwencji. Potem trzeba porównać te ciągi metodą „każdy z każdym” i tym samym wyznaczyć miary odległości — różnicy — między tekstami. Spośród licznych miar stosowanych w stylometrii w niniejszym badaniu wykorzystano bardzo skuteczny wariant pierwotnego wzoru tzw. Delty Burrowsa (Burrows, „Delta…” 2002), w którym zastosowano kosinus kąta między wektorami częstości słów dla każdej pary tekstów (Smith, Aldridge 2011). „Delta kosinusowa” (∆<) dla dwóch tekstów T i T1 mierzy więc kąt < (im mniejszy, tym te teksty są bardziej do siebie podobne):

wyliczany na podstawie podobieństwa kosinusowego tzw. standaryzacji Z dwóch wektorów
x = z(T) i y = z(T1):
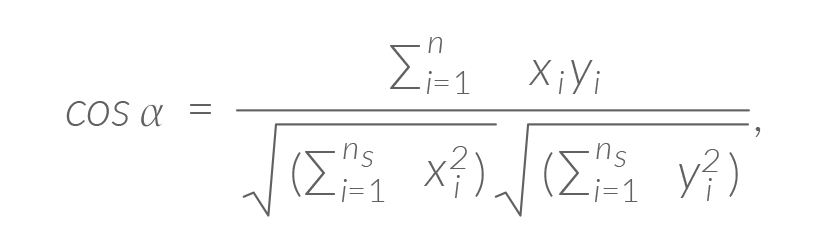
gdzie ns to liczba badanych słów, a z(T) to wartość standaryzacji Z częstości słów
w tekście T, liczona wzorem:

gdzie z kolei fs(T) to częstość bezwzględna słowa s w tekście T, μs to średnia częstość słowa s w zbiorze tekstów, do którego należy tekst T, a σs to odchylenie standardowe częstości słowa s w tym samym zbiorze tekstów; właśnie standaryzacja Z jest odpowiedzialna za uniezależnienie wyników od rozmiarów próbki — w realistycznych granicach, bo teksty muszą być wystarczająco długie (Eder 2015, Evert i wsp. 2017). Jak już powiedziano powyżej, miara odległości ∆< liczona jest dla każdej pary tekstów, co dla całego zestawu tekstów daje macierz odległości w całym korpusie. I choć już poszczególne wartości macierzy pokazują, które teksty są do siebie podobne, a które nie, najczęściej stosuje się dwuwymiarowe wizualizacje, sporządzane za pomocą metod statystycznych — takich jak analiza skupień, która łączy ze sobą najbardziej podobne teksty w ramach całej kolekcji. Tak oto wielowymiarowa przestrzeń stworzona przez teksty całego korpusu i wszystkie użyte w analizie słowa zostaje zredukowana do czegoś, co można przedstawić graficznie na wykresach. To właśnie dzięki takiej stylometrii — opartej na statystyce najczęstszych słów — wiemy już na pewno, że Szekspir i Marlowe wspólnie pisali przynajmniej jedną część Henryka VI (Craig, Burrows 2012); że to Apulejusz jest autorem niedawno odkrytego tekstu łacińskiego Compendiosa expositio (Stover i wsp. 2016); że J.K. Rowling i „Robert Galbraith” to jedna i ta sama osoba (Juola 2015); że Harper Lee stworzyła i Zabić drozda, i Idź, postaw wartownika (Choiński i wsp. 2017); i wreszcie, że Elena Ferrante to nie kto inny jak Domenico Starnone (np. Rybicki 2018).
Zastosowanie tych samych metod do przekładów daje może jeszcze ciekawsze wyniki, bo w tym przypadku dochodzi do swoistej „walki” dwóch sygnałów: autora i tłumacza. Nie ma tu żadnego stylometrycznego „uniwersalium tłumaczeniowego”, bo dotychczas przeprowadzone badania ujawniają bardzo różne tendencje. Zdarza się, że jedni tłumacze mają własny, indywidualny „sygnał”, a drudzy go nie mają: np. wśród licznych angielskich tłumaczy Sienkiewicza odrębną „stylometrię” posiada tylko W.S. Kuniczak, który Sienkiewicza adaptuje i (językowo) modernizuje raczej, niż przekłada (Rybicki 2006, 2013). Z kolei w przekładzie powieści Virginii Woolf Noc i dzień, rozpoczętym przez Annę Kołyszko, a po jej śmierci dokończonym i stylistycznie ujednoliconym przez Magdalenę Heydel, stylometria potrafiła wykryć, w którym miejscu nastąpiła zmiana tłumaczki (Rybicki, Heydel 2013).
Właśnie ten ostatni wynik — świadczący o stylometrycznej „widzialności tłumacza” w sytuacji, gdy mamy do czynienia z jednym oryginałem, przełożonym na ten sam język przez wielu tłumaczy — pozwalał mieć nadzieję, że Sienkiewicz po włosku okaże się wdzięcznym przedmiotem stylometrycznych eksperymentów; tym bardziej że zadanie mogło wydawać się łatwiejsze: nie chodziło przecież (jak w powyżej przywołanej pracy) o poszukiwanie dokładnego miejsca zmiany tłumaczki w celowo ujednoliconym tekście, lecz o efekty pracy różnych tłumaczy i – najwyżej — garstki plagiatorów.
Analizę jakościową i ilościową zebranych przekładów[1] przeprowadzono równolegle, na bieżąco konsultując i porównując uzyskane wyniki, a także przeprowadzając dodatkowe testy stylometryczne dla sprawdzenia hipotez wysuniętych w wyniku lektury jakościowej. Przygotowawcza analiza stylometryczna miała charakter przede wszystkim atrybucyjny i pozwoliła na wstępne ustalenia stopnia podobieństwa między poszczególnymi przekładami i/lub adaptacjami, co stało się podstawą do wytypowania próbek tekstów poddanych kolejnym badaniom ilościowym. Oprócz stylometrii badającej ciągi frekwencji najczęstszych słów zastosowano cztery inne metody ilościowej analizy podobieństw i różnic między badanymi przekładami, które zostaną opisane — wraz z ich rezultatami — w kolejności od najprostszej do najbardziej złożonej.
W wyniku wstępnej analizy ilościowej i jakościowej, które pozwoliły na wyeliminowanie z zebranego korpusu ewidentnych plagiatów i tekstów bardzo do siebie podobnych, liczba tekstów wytypowanych do badań została ograniczona do 21 przekładów i 12 adaptacji ujętych w tabeli.
