
Podsumowanie
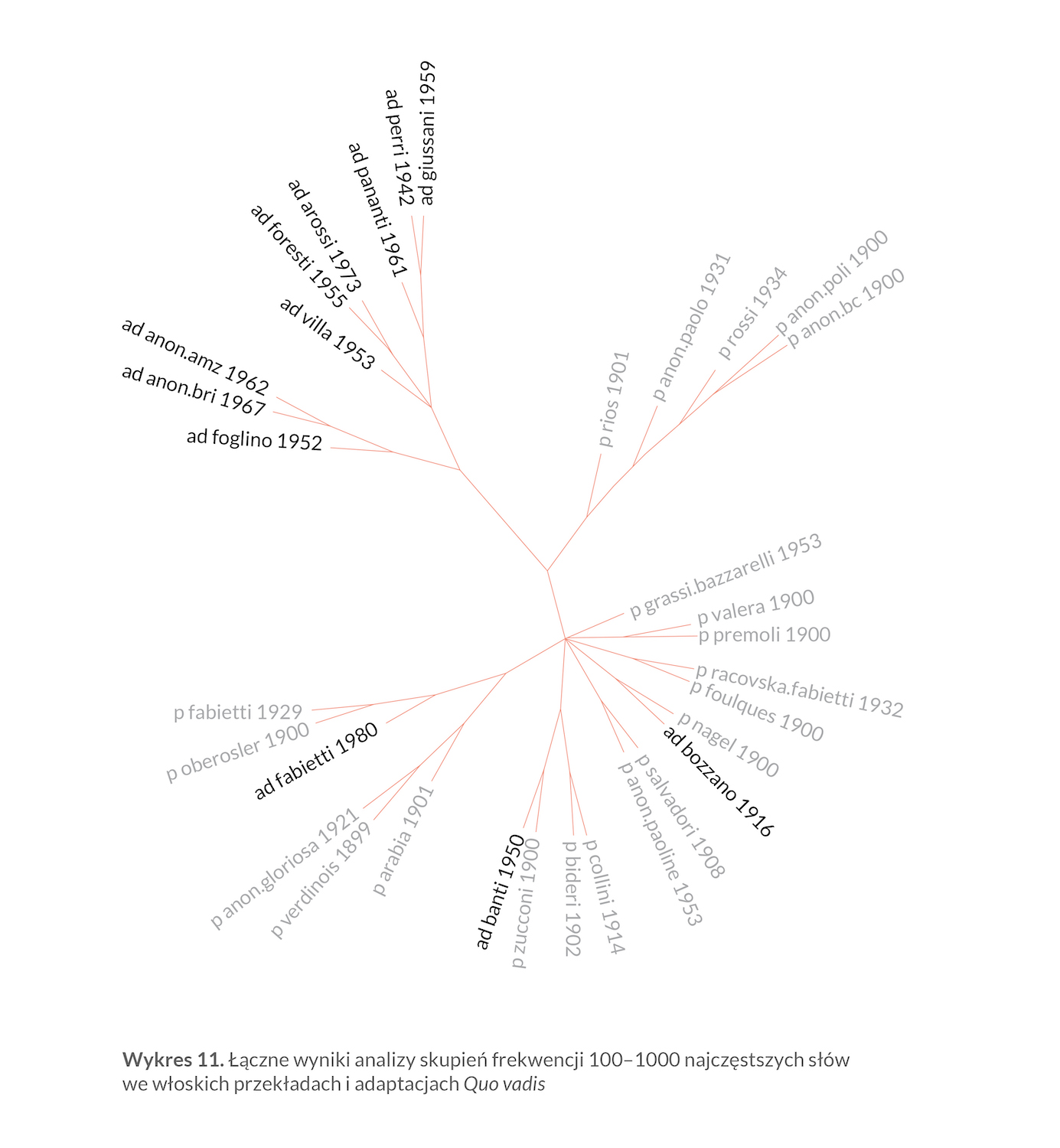
Zastosowanie metod ilościowych w badaniach nad dostępnym — z konieczności nieco okrojonym — korpusem włoskich wersji Quo vadis Henryka Sienkiewicza miało dwa główne cele. Po pierwsze, chodziło o próbę wykrycia tak silnych związków między poszczególnymi tekstami, że mogłyby one sugerować plagiat lub przynajmniej bezpośredni wpływ danego przekładu na późniejsze wersje, czyli stworzenie przekładoznawczego odpowiednika „drzewa manuskryptów” — takiego, jakie tworzy się w badaniach nad działalnością średniowiecznych kopistów. To zagadnienie jest zresztą bardzo pokrewne jednemu z głównych zastosowań stylometrii, czyli tzw. nietradycyjnej (bo nieopartej wyłącznie na jakościowych przesłankach wewnątrztekstowych) atrybucji autorskiej. Po drugie — jak już wielokrotnie wspomniano — chodziło o odczytanie na dystans korpusu zebranego — dosłownie — „w ciągu kilku lat i w niemałym trudzie”. Uzyskane wyniki w wielu punktach potwierdziły wnioski wyciągnięte z lektury jakościowej — albo przynajmniej pomogły ją ukierunkować. Tak było np. z odkryciem zależności między anonimowymi wersjami wydawnictw Società Anonima Editrice „La Poligrafica” i Baldini & Castoldi z 1900 roku oraz wersją Irmy Rios z 1901 roku i dużo późniejszym plagiatem Paolo De Rossiego z 1931 roku. Znalezienie wspólnego, stylometrycznego mianownika dla większości adaptacji/skrótów włoskich Quo vadis jest niewątpliwie interesujące — choć można by wysunąć obiekcję: by odkryć, że dana wersja jest skrótem, nie trzeba stosować aż programów komputerowych, wystarczy popatrzyć na liczbę stron. Ważne jest jednak potwierdzenie generalnej (choć nie bezwyjątkowej) tendencji do uproszczenia bogactwa słownictwa w adaptacjach. Jeszcze ważniejsze jest stwierdzenie będące wynikiem analizy ilościowej frekwencji najczęstszych słów — że adaptacje od pełnych przekładów odróżnia nie tylko długość tekstu czy nawet nie wspomniane bogactwo słownictwa; że różnica ta polega też na sposobie używania języka — czego wypadkową są właśnie różnice w proporcjach najczęstszych słów.
Przeprowadzone badania pokazały również, że analiza ilościowa ma ograniczenia i nie można bezwzględnie ufać jej wynikom. Okazało się, że człowiek może „przechytrzyć” program komputerowy: niektórzy z włoskich plagiatorów (np. Arabia i Collini) tak sprytnie manewrowali zawłaszczonym materiałem, że nie zdemaskował ich ani WCopyFind, ani Tracer; jednoznacznego werdyktu nie była też w stanie wydać analiza sieciowa skupień częstości słownictwa. Nie sposób nawet określić — a przynajmniej nie udało się tego zrobić na prezentowanym materiale — czy istnieje jakaś magiczna granica podobieństwa między tekstami, oddzielająca naturalną zbieżność między przekładami tego samego tekstu od zwykłego plagiatu. To również bardzo cenna lekcja, która powinna stać się inspiracją do rozwijania nowych, coraz bardziej precyzyjnych narzędzi stylometrycznych. Celem stylometrii nie jest bowiem zastąpienie tradycyjnych metod badań humanistycznych i lektury jakościowej tekstu. Wręcz przeciwnie: czytanie na dystans ma wspomagać close reading choćby tak samo skromnie, jak wyniki laboratorium medycznego wspierają diagnozy lekarza.