
Analizy statystyczne
Przykładem podejścia statystycznego są różne zestawienia metadanych tekstu. Kathearine Bode korzystała z australijskiej bibliografii literackiej, by pokazać jak w latach po II wojnie światowej rósł odsetek autorek wśród twórców powieści, co jednocześnie nie znajdowało odzwierciedlenia w artykułach naukowych i tekstach prasowych poświęconych literaturze (Bode 2014, 132 i 134). Do podobnych wniosków można dojść na podstawie danych z bibliografii tekstów drugich (Il. 1), gdzie jasno widać stopniowo zmniejszającą się dysproporcję pomiędzy autorami (kolor czarny) a autorkami (kolor czarny)[1].

Il. 1 Odsetek mężczyzn i kobiet wśród autorów „Tekstów Drugich” (za: Maryl 2016: 449)
Dane o publikacjach można dalej przetwarzać, np. wydzielając na podstawie liczby publikacji dużych i małych wydawców, by porównać przemiany w czasie i produkcji, jak na ilustracji nr 2 (za: Maryl 2017).
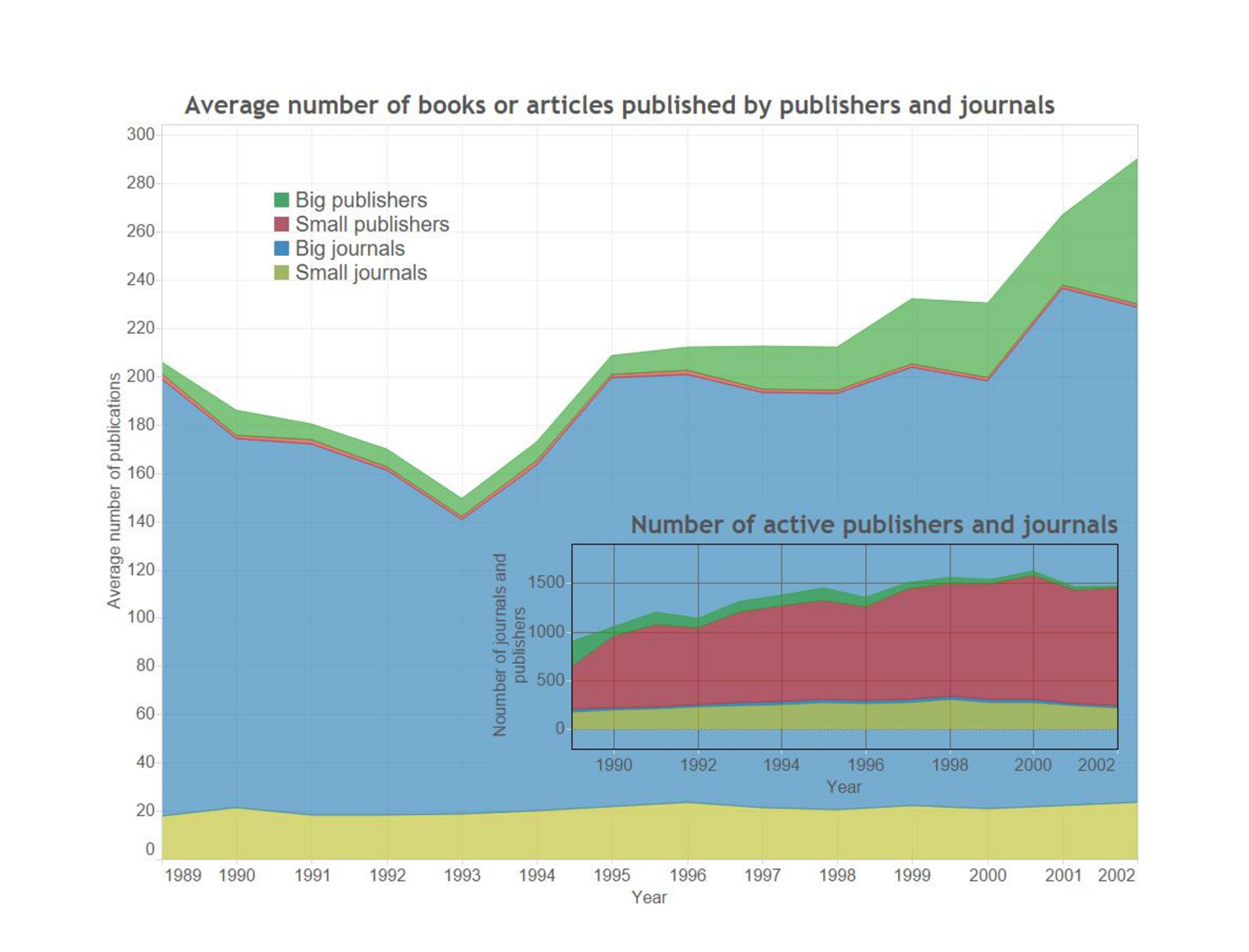
Il. 2 Liczba książek i artykułów publikowanych przez duże i małe czasopisma oraz wydawców (za: Maryl 2022)
Badania można prowadzić też na podstawie paratekstów i metadanych. Moretti (2013:183) analizował długość tytułów powieścowych lat 1740-1840, ukazując stopniową standardyzację tego paratekstu. Ten sam autor, na podstawie metadanych genologicznych, zaprezentował wykres sezonowości gatunków powieści brytyjskiej 1740-1900 (2005: 19).
Podobne wizualizacje można wykonywać, wykorzystując dane geograficzne, na przykład do pokazania produkcji literackiej na danych obszarach. Na przykład w serwisie Europejskiej Bibliografii Literackiej można wizualizować miejsca związane z publikacją utworów twórców z zasobów połączonych bibliografii, np. Adama Mickiewicza (Il. 3)
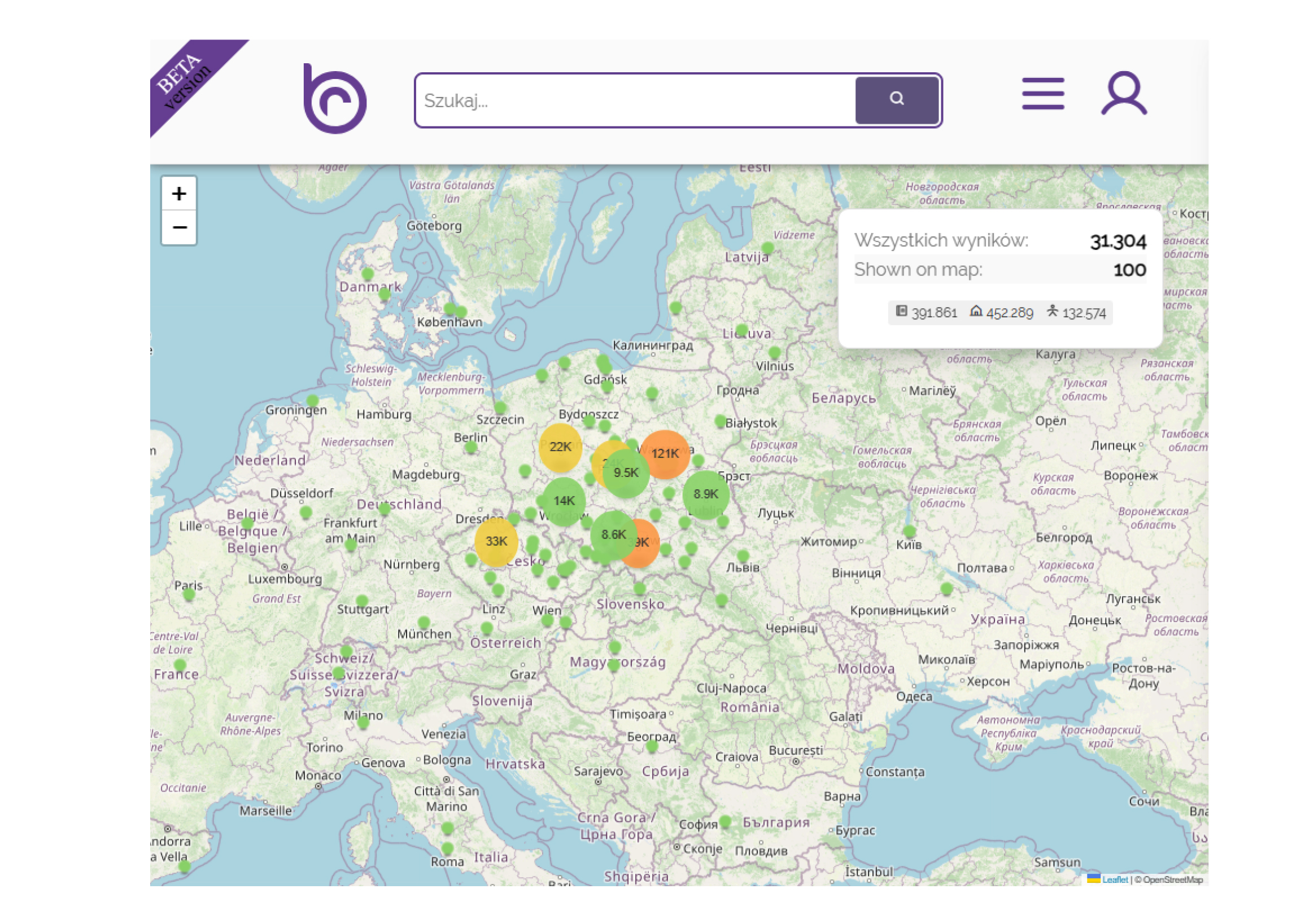
Il. 3 Wizualizacja miejsc związanych z publikacją dzieł Adama Mickiewicza, źródło: literarybibliography.eu
Zestawienia metadanych nie muszą mieć formy chronologicznej czy przestrzennej – jak wizualizacja 100 najczęściej cytowanych autorów w Tekstach Drugich (Il. 4. za: Maryl 2016).

Il. 4 Sto najczęściej cytowanych autorów w „Tekstach Drugich” (za: Maryl 2016: 452)
Przypisy
- Maryl, Maciej. „Tekstów Świat. Przyczynek Do Makroanalitycznej Monografii Czasopisma Literaturoznawczego.” In Projekt Na Daleką Metę. Prace Ofiarowane Ryszardowi Nyczowi., 443–62. Warsaw, Poland: Wydawnictwo IBL, 2016.