
Cyfryzacja procesu badawczego
Na wszystkich etapach procesu badawczego, od znajdowania i pozyskiwania danych, poprzez ich przechowywanie, analizę, interpretację i publikację – korzystamy dziś z metod i narzędzi cyfrowych. Szczegółowe rozważania dotyczące przemian w tym zakresie zachodzących w szeroko pojętej humanistyce zawiera raport grupy roboczej ALLEA e-humanities (Harrower et al. 2020), w tym miejscu skupimy się na tym, jak zmieniają się praktyki literaturoznawcze.
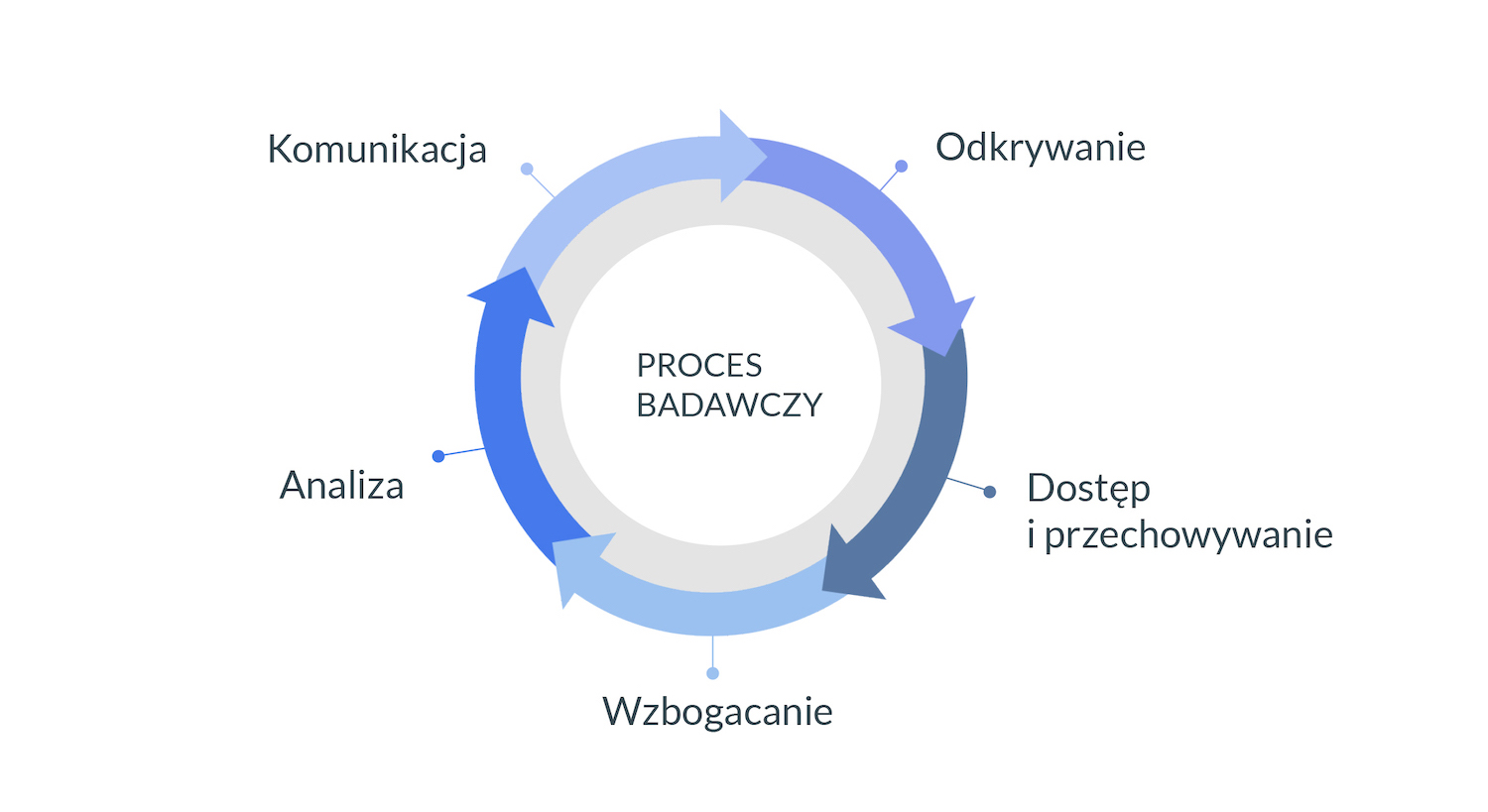
Il. 1 Proces badawczy, oprac. własne
Po pierwsze, samo odkrywanie materiałów odbywa się dziś online przy pomocy wyszukiwarek, specjalistycznych baz danych czy nawet sieci społecznościowych. Mamy komercyjne narzędzia nienaukowe jak wyszukiwarki (Google, Bing) czy portale społecznościowe z wyspecjalizowanymi grupami i sieciami kontaktów. Ponadto, dysponujemy wyspecjalizowaną naukową infrastrukturą publiczną (bibliografie, biblioteki, repozytoria) i komercyjną (bazy danych artykułów, akademickie portale społecznościowe). Te narzędzia działają tym skuteczniej, im lepiej indeksowane są treści naukowe – pełne teksty artykułów czy słowa kluczowe. Istotna jest także agregacja danych z różnych źródeł i dopuszczenie złożonych kwerend. Dlatego też jakość wyszukiwania jest ściśle powiązana z efektami kolejnych kroków procesu badawczego, w szczególności z publikowaniem otwartych danych i treści.
Po drugie, dostęp do źródeł jest możliwy dzięki kumulatywnemu przyrostowi materiałów za sprawą prac digitalizacyjnych i publikowania danych badawczych zebranych bądź wytworzonych w różnych projektach. Co więcej, dokumenty, które powstały wcześniej w innym celu – jak bibliografie, słowniki, leksykony – po przetworzeniu cyfrowym stają się istotnymi źródłami danych i wiedzy. Dodatkowo, do przechowywania służą nam coraz częściej wyspecjalizowane narzędzia – jak dzielone dyski do pracy grupowej czy menedżery bibliografii.
Humanistyka cyfrowa wspomaga te procesy, formułując wskazówki dotyczące udostępniania danych badawczych spełniających kryteria FAIR (findable, accessible, interoperable, reusable), czyli wyszukiwalne, dostępne, interoperacyjne i nadające się do ponownego wykorzystania. Przedcyfrowe dane badawcze w literaturoznawstwie ograniczały się do drukowanych transkrypcji, edycji czy zestawień statystycznych bądź chronologicznych. Dzięki cyfrowej formie danych, spektrum możliwości jest dużo rozleglejsze, co pozwala na zachowanie i ponowne wykorzystanie wyników badań z innych projektów. Wraz z Martą Błaszczyńską i Bartłomiejem Szleszyńskim i na podstawie warsztatów z literaturoznawcami i literaturoznawczyniami wyróżniliśmy następujące typy danych literaturoznawczych: tekst kultury (egzemplarz utworu), metadane (opis egzemplarza), adnotacje (notatki, komentarze, uwagi, aparat krytyczny, znaczniki), dane kultury literackiej (kalendaria, listy osób i zdarzeń, statystyki), literatura przedmiotu (interpretacje, podręczniki, świadectwa odbioru) oraz dokumentacja procesu badawczego (metodologia, notatki) (por. szersze omówienie w Maryl, Błaszczyńska, Szleszyński, et al. 2021).
Po trzecie, dokumenty, z którymi pracujemy, anotujemy znacznikami cyfrowymi, co pozwala lepiej z nich korzystać (np. przy wyszukiwaniu treści) i łatwiej łączyć z innymi materiałami oraz tekstami. Na przykład, cyfrowa edycja naukowa powstaje z połączenia tekstu, obrazu, aparatu krytycznego i anotacji (ibid. akapity 29-30). Te ostatnie można dodawać ręcznie lub automatycznie, m. in. dzięki narzędziom rozpoznającym i tagującym nazwy własne czy hasła przedmiotowe. Wzbogacanie materiału łączy się z jego dostępnością – tekst wzbogacony i udostępniony wchodzi do globalnego zasobu, może być wykorzystany przez innych i pozwala na kumulatywne korzystanie z wiedzy czy źródeł. Co równie ważne, tekst przygotowany w standardowym formacie, można dalej przetwarzać maszynowo i wykorzystywać w badaniach lub w wyszukiwarkach.
Po czwarte, analiza i interpretacja są wspomagane cyfrowo. Oczywiście możemy tu wyróżnić typy badań pod względem złożoności komponentu cyfrowego – na przykład wskazać bardzo zaawansowane badania humanistyki cyfrowej, do których należą analiza stylometryczna (np. Eder 2014), badanie sieci relacji między postaciami (np. Kubis 2021), czy analizy socjologiczno-literackie na podstawie danych (np. Umerle and Rosiński 2018). Cyfrowa forma tekstu pozwala także na jego wstępne przetwarzanie i przygotowanie do tradycyjnej interpretacji. Na przykład, można wyszukać wystąpienia i kontekst konkretnych słów, a w bardziej zaawansowanych wariantach badać wydźwięk kontekstu lub tworzyć sieci postaci, które to dane następnie wspomagają proces interpretacji utworu.
Po piąte, nowe cyfrowe formy publikacji pozwalają nam uwolnić się od ograniczeń drukowanego tomu i powiązać wypowiedź naukową z danymi czy ikonografią. Interaktywne formy komunikacji, jak platformy internetowe, dają też możliwość lepszego udostępnienia źródeł i wyjścia poza ramy tekstowego eseju czy monografii. Tu przykładem znowuż może być edycja cyfrowa (np. edycja korespondencji Skamandrytów na platformie tei.nplp.pl) czy rozszerzona monografia (np. internetowa wersja Sienkiewicza ponowoczesnego), ale też baza danych (np. Atlas Literatury Zagłady). Dodatkowo, nowe formaty muszą być otwarte na wersjonowanie, kolejne wersje tekstu są aktualizowane czy dodawane – tu za przykład może posłużyć OPERAS living book, który zbiera różne raporty konsorcjum OPERAS, pozwalając na zmiany i komentarze społeczności[1].
Po szóste, komunikacja badawcza jest zapośredniczona cyfrowo. Dotyczy to zarówno kontaktu z publicznością, jak i nowych form angażowania jej w badania i pracę naukową, jak crowdsourcing. Zarówno Komisja Europejska, jak i nasze rodzime Ministerstwo kładą nacisk na to, by wiedza miała wpływ (impact) społeczny, czyli były w jakimś wymiarze przydatne dla społeczeństwa. Nie wdając się tu w rozważania o typach wpływów badań humanistycznych (które są różnorodne i przede wszystkim długofalowe), ograniczamy się do stwierdzenia, że cyfrowe formy komunikowania wyników ów wpływ wzmacniają, przybliżając dane i wyniki w przystępnej formie. Zmienia się też rola publiczności w badaniach, która w duchu open notebook science coraz częściej dostaje wgląd w kolejne etapy procesu badawczego, np. przez strony czy blogi projektów, ich profile w mediach społecznościowych.
Po siódme, narzędzia cyfrowe wspomagają pracę zespołową, upowszechniając nowe formy prowadzenia badań, wzmacniając tendencje „laboratoryjne” w humanistyce. Z jednej strony można powiedzieć że wraz z metodami cyfrowymi do literaturoznawstwa i innych dyscyplin humanistycznych przenikają z innych dyscyplin nowe sposoby uprawiania nauki; z drugiej, można też dostrzec powrót do pracy zespołowej znanej z dużych projektów dokumentacyjnych, prowadzonych w literaturoznawstwie od dekad.
Przypisy
- Szczegółowy opis problematyki w: Janneke Adema, Marcell Mars i Tobias Steiner Books Contain Multitudes: Exploring Experimental Publishing. COPIM Project 2021. https://doi.org/10.21428/785a6451.933fa904. [Dostęp 8 IX 2022]. Zob. także: Maciej Maryl, Marta Błaszczyńska, Agnieszka Szulińska, Anna Buchner, Piotr Wciślik, Iva Melinščak Zlodi, Jadranka Stojanovski, et al., OPERAS-P Deliverable D6.5: Report on the Future of Scholarly Writing in SSH, OPERAS project 2021, https://doi.org/10.5281/zenodo.4922512. [Dostęp 8 IX] 2022