

Historia powstania
Baza tekstów to obecnie zbiór kilkuset tekstów XVI wiecznych zaczerpniętych z druków (a także niewielkiej liczby rękopisów) opracowanych na jednolitych zasadach. Z punktu widzenia opracowania Słownik składa się z dwóch zasobów – tzw. podstawowego kanonu źródeł oraz tekstów uzupełniających. W portalu spxvi.edu.pl udostępniono w tej chwili kanon podstawowy o objętości 56 milionów znaków[1], jego unikatową cechą są jednolite zasady transliteracji, jakiej poddano wszystkie teksty. Transliteracja jako sposób opracowania dawnego zapisu najbliższy oryginałowi (poza jego reprodukcją w dowolnej technice), dostarcza najbardziej autentycznego materiału językowego, a jednocześnie przez wprowadzone konsekwentnie jednolite zasady umożliwia zestawianie i porównywanie materiałów zróżnicowanych chronologicznie, geograficznie, tematycznie, gatunkowo itd.
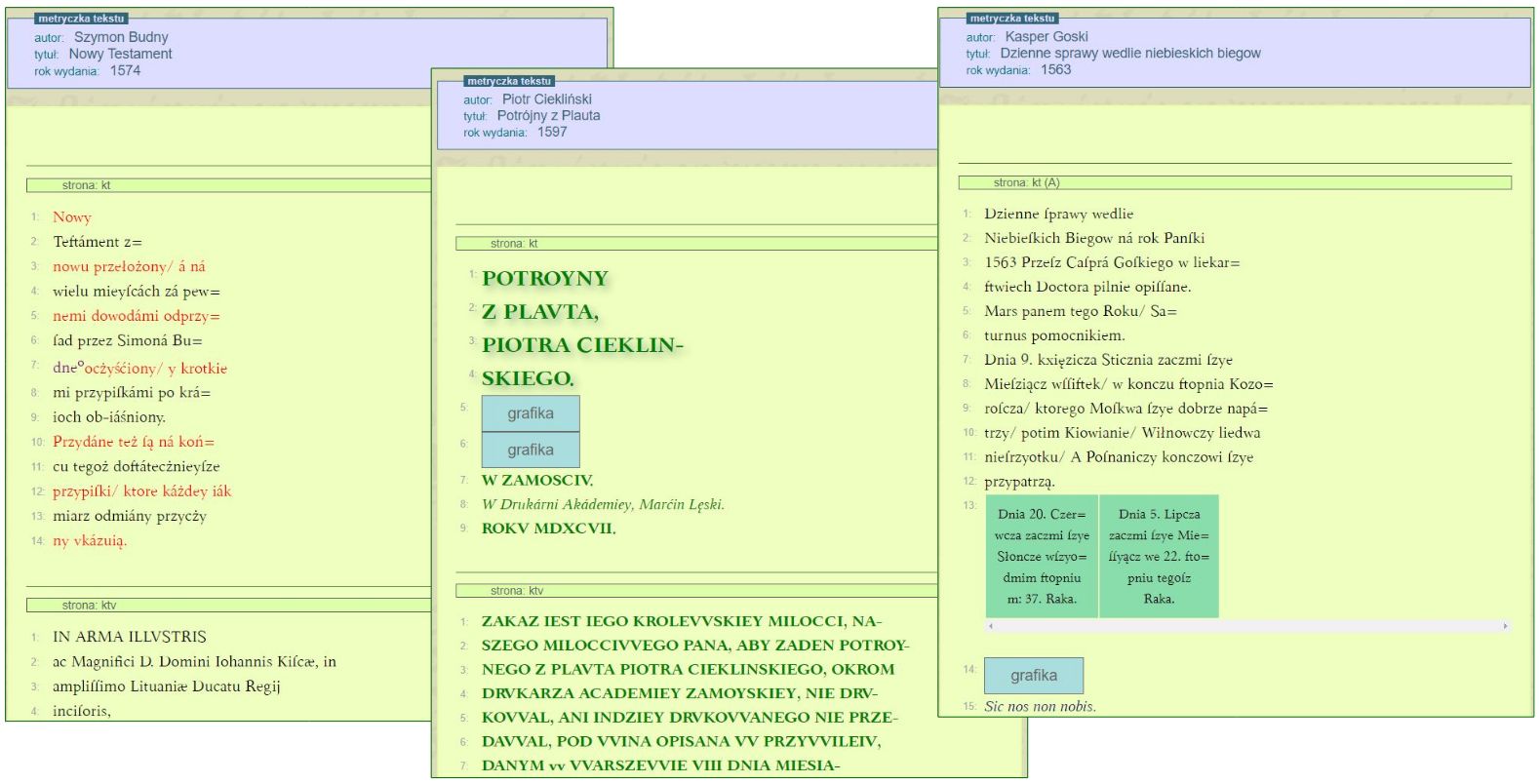
Il. 2. Prezentacja tekstów z bazy, źródło: spxvi.edu.pl
Historia powstania
Pierwotnie baza tekstów powstała jako materiały źródłowe dla Słownika polszczyzny XVI wieku – z założenia słownika dokumentacyjnego odwołującego się tylko i wyłącznie do tego, co poświadczone w przekazach szesnastowiecznych. Ambitnym zamiarem twórców była kompletność: „Słownik musi tak sobie ułożyć listę źródeł, by móc sformułować uzasadnione przekonanie, iż odwołał się do wszelkich możliwych zadokumentowanych zastosowań języka. […] Zdajemy sobie sprawę, że postulat kompletności słownictwa jest oczywista tym ideałem, którego żadna praktyka zrealizować nie może.” (Wstęp. Charakter „Słownika” 1956, VII).
Dobór tekstów
Dążąc do spełnienia postulatu kompletności (realistycznie ograniczonego do „szeroko rozumianego centralnego zasobu słownikowego” – Wstęp. Charakter „Słownika” 1956, XIII), wyłoniono zespół tekstów stanowiących bazę materiałową Słownika, na którą składają się 272 jednostki (w tym wiele drobnych i nie stanowiących wyodrębnionej samodzielnej jednostki edytorskiej, takich jak wstępy, dedykacje itp.), dbając w miarę możności (znacząco ograniczonej w wypadku tak odległej epoki) o ich reprezentatywność regionalną, chronologiczną, gatunkową itd. Wstępnie przyjęto zasadę reprezentacji statystycznej – dla tekstów powyżej 150 tysięcy znaków założono włączenie do bazy tekstów tylko 50% ich objętości, a powyżej 300 tysięcy znaków zaledwie 20%. Zasada ta jednak w toku badań upadła, w hołdzie dla „wybitnych indywidualności, którym przypisuje się odzwierciedlanie głównego toru rozwojowych tendencji języka” (Mayenowa 1966, IX) (dlatego wprowadzono np. w 100% liczącą ponad dwa i pół miliona znaków Kronikę M. Bielskiego) oraz „powiązanie z serią Biblioteka Pisarzy Polskich Instytutu Badań Literackich, zawierającą pełne wykazy słów użytych w tekście, [które] kazało się wycofać w praktyce z dotychczasowej metody opracowania próbek statystycznych” (Mayenowa 1966, XII).
Metody opracowania
Wyłoniony w latach pięćdziesiątych kanon tekstów szesnastowiecznych przepisano stosując transliterację (skrócone zasady transliteracji – patrz: Instrukcja do zbierania materiałów 1956, XXI-XXII, także: Górski i in.1955[2], 52-63). Techniczne szczegóły omawia Instrukcja do zbierania materiałów dla kartoteki „Słownika polszczyzny XVI wieku” (1956, XX-XXI), wytypowane teksty przepisano na maszynie w postaci tzw. „matryc” – kart A4 podzielonych na 4 części i skopiowanych (metodą powielaczową) co najmniej tyle razy ile form wyrazowych wyróżniono w tekście na powstałej w ten sposób karcie. Pocięte karty utworzyły fiszki do kartoteki materiałowej Słownika.
Il. 3. Pohasłowane fiszki w kartotece Słownika i przykład matrycy, z której je uzyskano, źródło: archiwum pracowni.
Jednocześnie stworzono również biblioteczkę tzw. egzemplarzy archiwalnych – transliterowanych, przepisanych maszynowo i powielonych tekstów w oprawach introligatorskich, które stanowią do dziś jeden z podstawowych zasobów pomocniczych w Pracowni Słownika Polszczyzny XVI wieku. Ich objętość ocenia się na około 41 tysięcy stron maszynopisu, jest to z pewnością najobszerniejszy zbiór jednolicie opracowanych polskojęzycznych tekstów dawnych. Zróżnicowany, lecz obejmujący przy tym sztandarowe zabytki literackie XVI wieku, a przynajmniej reprezentacyjne przykłady twórczości piśmienniczej tego okresu. Pozostając jednak wewnętrznym dokumentem Pracowni, stopniowo ulegał zapomnieniu w środowisku naukowym poza nią, a w toku stałego użytkowania także degradacji.
Przypisy
- Dane te dotyczą czystego tekstu bez znaczników XML.
- Twórcy Słownika (m.in. S. Hrabec, W. Kuraszkiewicz, W. Taszycki, S. Saski, S. Rospond, a przede wszystkim M.R. Mayenowa i F. Pepłowski) uczestniczyli także w dyskusjach, ustalaniu zasad i przygotowaniu tej publikacji, Zasad wydawania tekstów staropolskich. Projekt.