
Remediacja złotego słownika
Wydobycie czystego tekstu – Import etap I

Il. 8 Ekran modułu poprawy importu danych (etap I); źródło: oprac. własne
W procesie konwersji papierowego źródła na bazę danych podstawowym zadaniem jest digitalizacja, czyli proces zamiany informacji zapisanej analogowo na jej reprezentację cyfrową. W przypadku złotego słownika, wydawanego w latach 1997-2007, sytuacja była dość skomplikowana. Digitalizacji drugiego stopnia – zgodnie z klasyfikacją Piotra Żmigrodzkiego (Żmigrodzki 2008: 102-103) – czyli doprowadzenia zawartości słownika do postaci graficznej z indeksowaniem i możliwością przeszukiwania dokonano wcześniej w ramach innego projektu zatytułowanego Cyfrowe zasoby dokumentacji literatury polskiej w wolnym dostępie (grant Ministerstwa Kultury i Dziedzictwa Narodowego z 2016 r.). Całość materiału istniała już w postaci plików PDF w Repozytorium Cyfrowym Instytutów Naukowych[1].
Po optycznym rozpoznaniu tekstu zapisanego jako PDF, a następnie dokonaniu automatycznej korekty OCR okazało się jednak, że ilość błędów w otrzymanej tą drogą wersji tekstowej plików nie pozwala oprzeć się na tym materiale. Jako że cyfrowej podstawy nie udało się pozyskać również od wydawcy złotego słownika (WSiP), sięgnięto do oryginalnych plików, zapisanych na dyskietkach w popularnym w latach 90. edytorze QR-Tekst[2]. Ze względu na specyficzne znaczniki formatowania, a także fakt, że był to materiał sprzed korekt autorskich i wydawniczych (wprowadzanych na wydrukach), ten przekaz także okazał się niewystarczający.
Pliki .qrt miały jednak tę przewagę nad wcześniejszym odczytaniem (tj. OCR z PDF), że zawierały znacznie mniej błędów literowych (zwłaszcza, jeśli idzie o znaki diakrytyczne w wyrazach obcych). Żeby osiągnąć oczekiwany rezultat skonfrontowano wyniki OCR i pliki archiwalne. Posłużył do tego specjalnie zaprojektowany moduł do kontaminacji obu źródeł (jego ekran przedstawia grafika powyżej). W tabeli podzielonej na 3 kolumny (z nagłówkami: QRT, PDF oraz QRT/PDF) zespół redaktorów technicznych analizował różnice i wybierał poprawne wersje. W trzeciej kolumnie (z nagłówkiem QRT/PDF) znajdował się tekst wyekscerpowany z plików .qrt z zaznaczonymi (kolorami) dyferencjami w stosunku do pliku zaczerpniętego z wersji PDF. Tylko to okno było edytowalne, a dodatkową pomocą służył mechanizm, dzięki któremu po ustawieniu kursora na spornym fragmencie tekstu, na ekranie pojawiały się podpowiedzi (zob. grafika niżej).
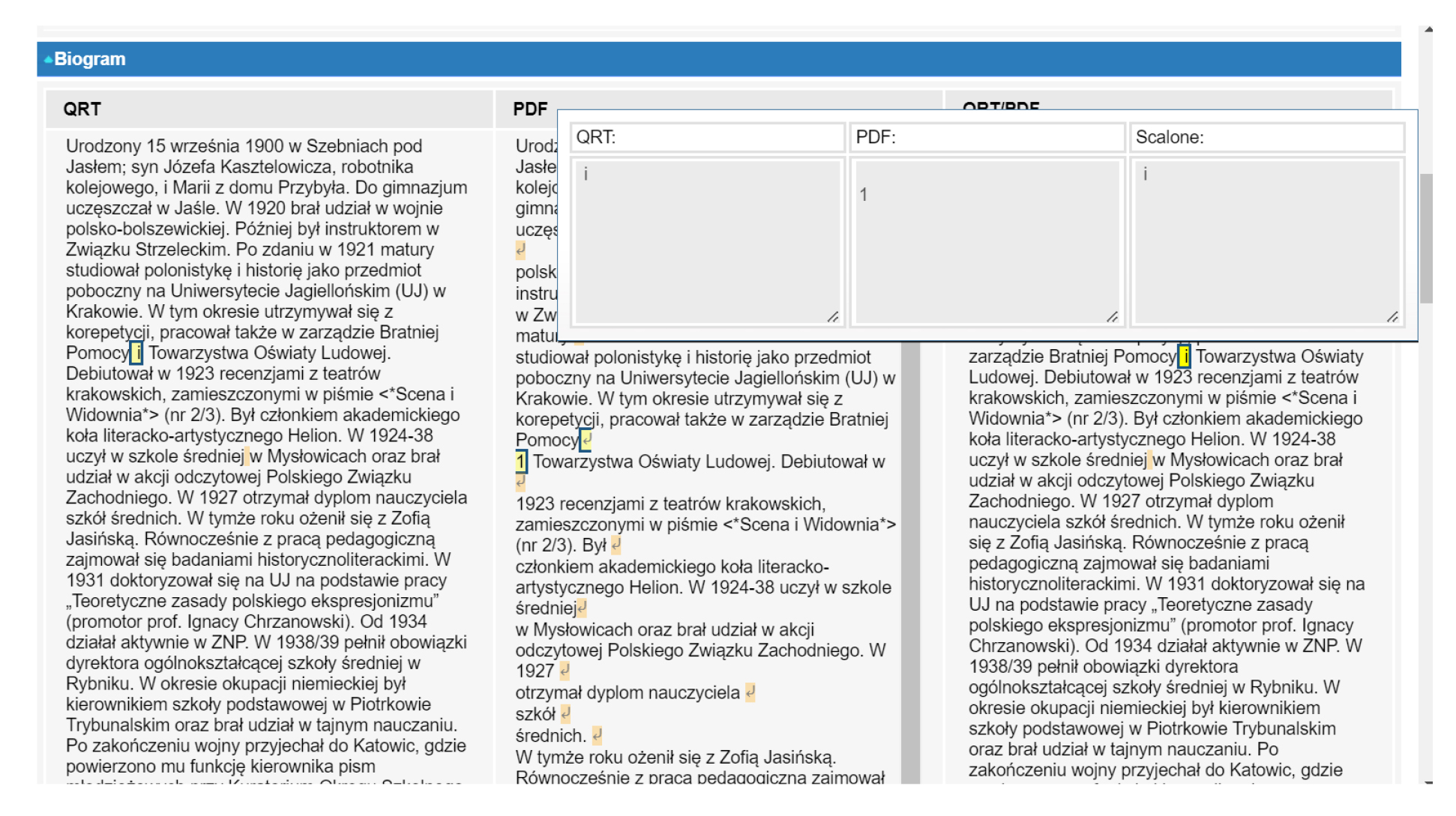
Il. 9 Ekran modułu poprawy importu danych (etap I) – edycja; źródło: oprac. własne
Parsowanie
Po zakończeniu wstępnej analizy i ustaleniu poprawnej treści każdego hasła można było przejść do etapu parsowania, tj. analizy składniowej ciągu znaków w celu wyodrębnienia jej struktury. Początkowo wydawało się, że hasło słownikowe to wystarczająco ustrukturyzowany byt tekstowy i przekształcenie jego treści przebiegnie w prosty sposób. Jednakowoż w przypadku złotego słownika wyodrębnianie niezbędnych fragmentów informacji znacznie utrudniała niejednolitość zasad redakcyjnych, stosowanych na przestrzeni 20 lat. Wynikająca stąd niehomogeniczność materiału (typowa, a nawet uznawana za walor kompendium drukowanego) była poważnym wyzwaniem dla parsera. Segregacja na biogramy oraz pozycje bibliograficzne przebiegała stosunkowo sprawnie. Problemów nastręczyła mnogość i niejednolitość nagłówków w dziale TWÓRCZOŚĆ. Był to efekt nacisku położonego w złotym słowniku na specyfikę twórczości poszczególnych autorów, a co za tym idzie – dopuszczenia sporego marginesu swobody w nazewnictwie ich dorobku i tytułach poszczególnych sekcji w haśle. Dodatkowych komplikacji przysparzał wielopoziomowy układ nagłówków, który wymagał zredukowania i zmian. W tym celu systemowo zdefiniowane zostały listy dopuszczalnych nagłówków, wzorowane na obu zaimportowanych słownikach, ale znacznie ujednolicone. Co więcej, redaktor naukowy i administrator otrzymali uprawnienia do tworzenia nowych nagłówków (nadrzędnych i podrzędnych) także po zakończeniu prac informatycznych, już podczas użytkowania systemu.
Niewątpliwym pozytywem pozostawał fakt, że proces digitalizacji trzeciego stopnia – do postaci bazodanowej – pozwolił wykryć i wyeliminować wiele błędów nie tylko w treści, lecz także strukturze złotego słownika.
Scalanie hasła – import etap II
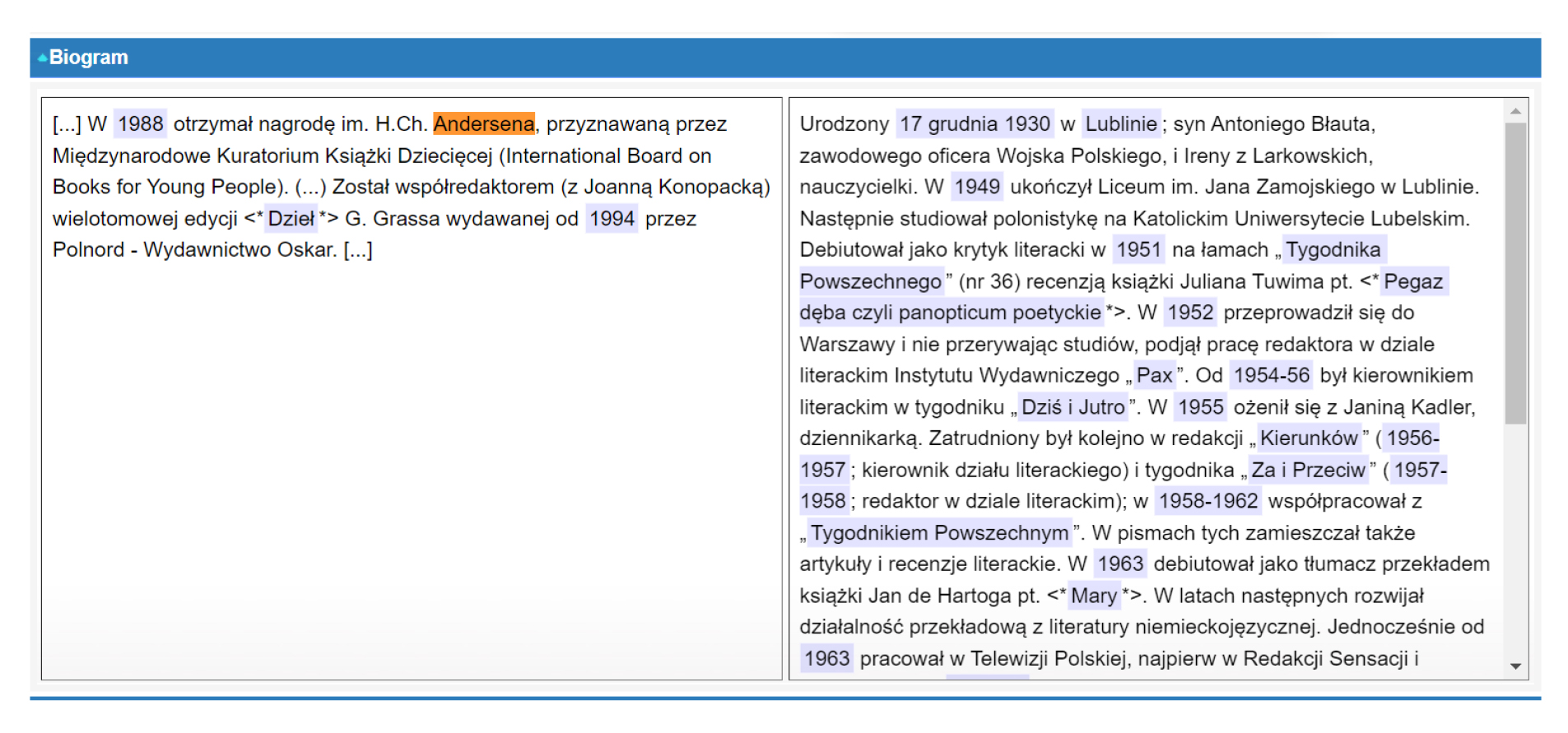
Il. 10 Ekran scalania biogramu (import – etap II); źródło: oprac. własne
Cierpliwe dopracowywanie reguł parsowania przyniosło efekt. Umieszczone w bazie hasła z tomów 1-9 złotego słownika wystarczyło tylko połączyć z uzupełnieniami z tomu 10. (które podlegały tym samym procedurom importu i parsowania, jak hasła główne). W panelu (skonstruowanym na użytek zespołu scalającego) w dwóch kolumnach wyświetlane było uzupełnienie sparowane z hasłem głównym, przy czym w zapisie drukowanym część informacji się powtarzała. Zadanie redaktora technicznego polegało na przeniesieniu tylko istotnych danych i wstawieniu ich, czasem po zmodyfikowaniu, w odpowiednie miejsce w haśle docelowym. Dla ułatwienia zastosowano podświetlenia tekstu – kolorem pomarańczowym wyróżniono edytowane pozycje, zielonym – pozycje dodane w uzupełnieniach i automatycznie zaciągane do hasła docelowego.
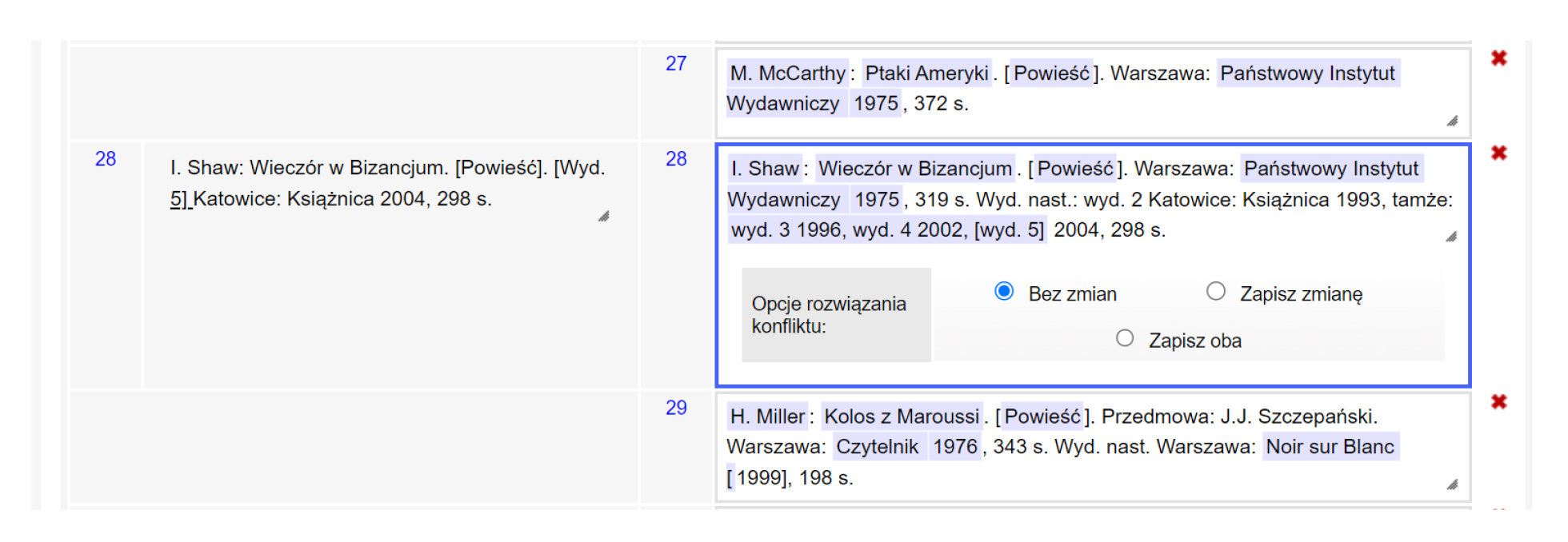
Il. 11 Ekran scalania pozycji bibliograficznych (import – etap II) – edycja; źródło: oprac. własne

Il. 12 Ekran scalania pozycji bibliograficznych (import – etap II) – przed edycją; źródło: oprac. własne
Na tym etapie przeprowadzono również automatyczne rozwiązywanie skrótów. Weryfikacja poprawności tego procesu należała także do kompetencji redaktorów technicznych.
Przypisy
- Zob.: www.rcin.org.pl/dlibra/publication/80114#structure
- Dodatkową komplikację stanowił fakt, że QR-Tekst, edytor polskiej firmy Malkom, współpracował z systemem operacyjnym DOS, który był już prawie niedostępny, a czytnik dyskietek posiadały w tym czasie tylko nieliczne komputery.