
Transformacja cyfrowa – etap II – przekształcenie w cyfrową infrastrukturę (2018-2023)
Automatyzacja pozyskiwania i przetwarzania danych bibliograficznych jako proces wewnętrzny (2018-2019)
Współczesne usługi bibliograficzne opierają się na systemach wymiany danych takich jak współkatalogowanie (Dwornik 2018) czy agregacja metadanych (Freire et al. 2018). Rozwiązania te opierają się na założeniu wykorzystywania rekordów bibliograficznych stworzonych przez inne podmioty dla własnych celów, dostosowując je w różnym stopniu. Umożliwia to ograniczenie dublowania wysiłków (dwie instytucje tworzą rekord bibliograficzny dla tej samej publikacji zupełnie niezależnie) i unikanie opóźnień bibliograficznym publikacji, których wolumen wzrasta od kilku dekad (Szymańska 2010; UNESCO).
Taka procedura jest współcześnie standardem prac bibliograficznych. W tym sensie transformację cyfrową dopełniać musi automatyzacja pozyskiwania i przetwarzania danych w postaci tworzenia narzędzi informatycznych oraz prowadzenia wewnętrznych programistycznych procesów automatyzujących przetwarzanie danych. Taką automatyzację wdrożono poprzez budowę narzędzia do automatycznego importu danych książkowych w ramach systemu do ręcznego tworzenia rekordów bibliograficznych (opracowanego przez współtwórcę bazy danych pbl.ibl.poznan.pl firmę ADVIS, od lat odpowiedzialną za utrzymywanie infrastruktury PBL). Pliki wsadowe do importera opracowywał sam zespół PBL poprzez pozyskiwanie i automatyczne przetwarzanie rekordów bibliograficznych Biblioteki Narodowej. W efekcie ok. 50 proc. rekordów dla każdego rocznika bibliografii nie wymagało interwencji bibliografa.
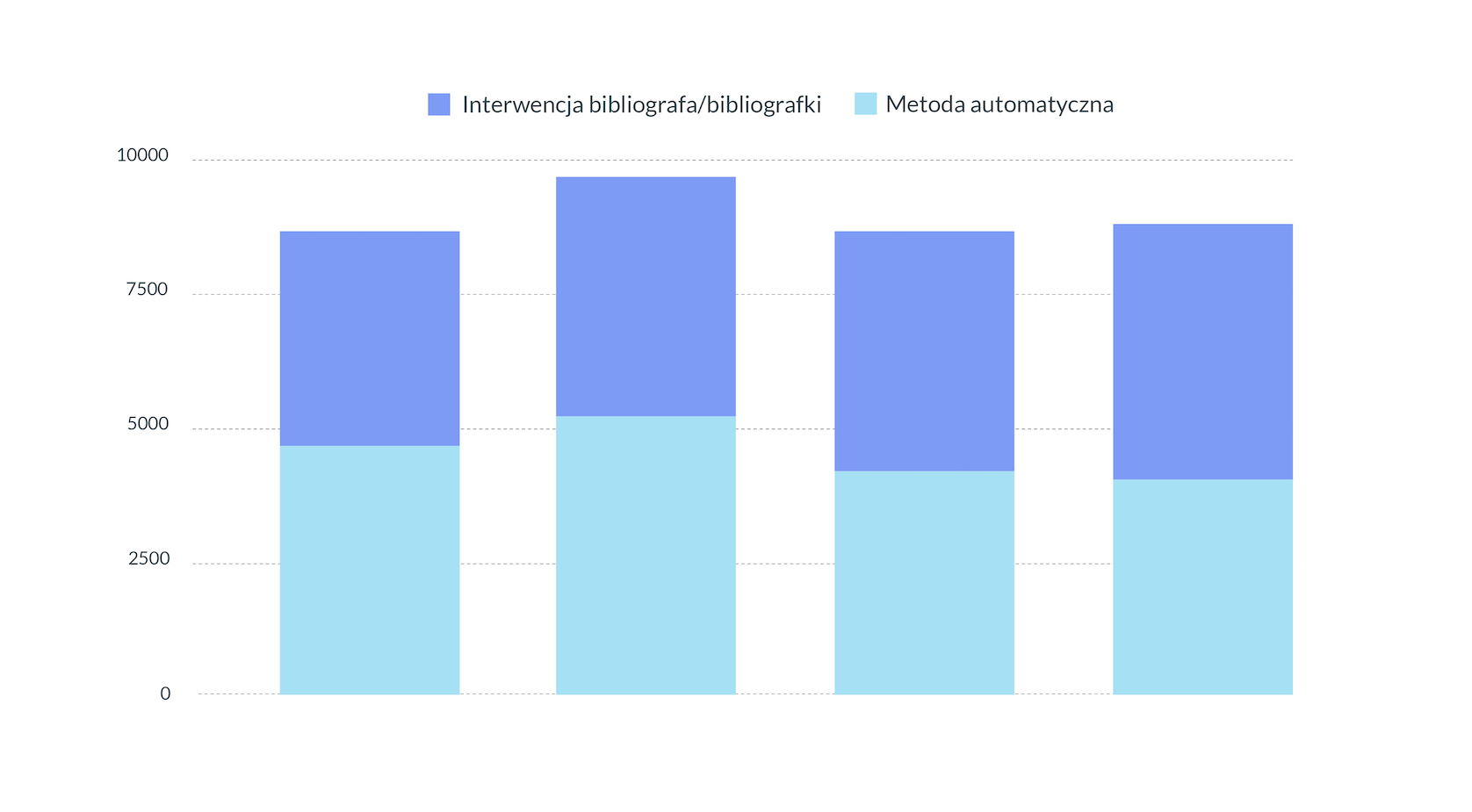
Il. 6 Wykres: Stosunek automatycznie pozyskiwanych i zachowanych rekordów do rekordów zmodyfikowanych przez zespół bibliograficzny dla poszczególnych roczników, źródło: oprac. własne
Pozostałe rekordy podlegały interwencji bibliograficznej, która zawsze będzie potrzebna – niemniej należy ją wykorzystywać tam, gdzie jest najbardziej konieczna, unikając dublowania wysiłków w ekosystemie pracy dokumentalistycznej. Mimo rozwoju automatyzacji prac bibliograficznych, podstawowym modelem prac jest więc metoda human-in-the-loop.
Pozyskanie środków na utrzymanie specjalnej infrastruktury badawczej (SPUBI) – zmiana modelu biznesowego
W celu utrzymania funkcjonowania infrastruktury PBL w roku 2020 pozyskano fundusze MEiN w ramach dotacji na utrzymanie specjalnej infrastruktury informatycznej (SPUBi). Oznaczało to przeformułowanie rozumienia roli i funkcjonowania bibliografii. Złożenie wniosku i realizacja projektu wymagała przede wszystkim zidentyfikowania grupy odbiorczej infrastruktury, którą stanowią projekty naukowe i badacze wykorzystujący ją do zaawansowanych prac badawczych i badawczo-rozwojowych (nie są to po prostu użytkownicy online bazy danych). Do takich wykorzystań należą zarówno użycia danych bibliograficznych, jak i informatycznych elementów infrastruktury, takich jak algorytmy przetwarzania danych czy elementy metody bibliograficznej. Wszelkie użycia tego rodzaju są identyfikowane i dokumentowane. W znaczący sposób warunkuje to dalszy rozwój infrastruktury i nastawienie jej twórców. W ramach projektu SPUBi, aby zapewnić konkurencyjność infrastruktury badawczej zaakcentowano rozwój bazy bibliograficznej w dwóch aspektach: automatyzacji pozyskiwania rekordów bibliograficznych oraz wdrażania standardów międzynarodowych.
Automatyzacja pozyskiwania rekordów bibliograficznych – kontynuacja
W projekcie SPUBi kontynuowano automatyzację pozyskiwania rekordów bibliograficznych poprzez utworzenie uniwersalnego importera danych bibliograficznych Biblioteki Narodowej służącego dostarczaniu danych bezpośrednio do nowej bazy danych pbl.ibl.waw.pl (bez pośrednictwa infrastruktury pbl.ibl.poznan.pl). Tym samym zasób najnowszej bazy danych został zaktualizowany do roku 2023, a dawna baza z programem edycyjnym i interfejsem dostępnym w domenie pbl.ibl.poznan.pl służy do prac manualnych, natomiast jej zawartość okresowo zasila bazę pbl.ibl.waw.pl. Metodę human-in-the-loop zastosowano również do prac nad retrospektywną konwersją zasobu drukowanych bibliografii PBL, gdzie prace manualne bibliografek i bibliografów wspierały automatyczne metody parsowania i identyfikacji rekordów rozwijane przez mgra Patryka Hubara w ramach rozprawy doktorskiej Metody automatycznej retrospektywnej konwersji bibliografii. Przykład “Polskiej Bibliografii Literackiej”.
FAIR: Interoperacyjność i standardy
Drugim aspektem projektu SPUBi było stałe dostosowywanie infrastruktury do zasad FAIR data, które wskazują, iż dane naukowe powinny być łatwo odnajdywalne (F = findable), dostępne (A = accessible), interoperacyjne (I = interoperable), gotowe do ponownego wykorzystania (R = reusable). Aby sprostać tym wymaganiom, zaimplementowano mapowanie oraz eksport danych w formatach MARC21 oraz formatach cytowań RIS i Bibtex oraz wdrożono szereg rozwiązań z zakresu Linked Open Data (LOD). Wzbogacenie znacznikami LOD oznaczało opatrzenie danych identyfikatorami zewnętrznymi (np. VIAF, GeoNames) i umożliwienie eksportu danych w formacie JSON-LD.
W wyniku automatyzacji i wdrażania zasad FAIR zasób bibliograficzny PBL jest atrakcyjniejszy dla użytkowników: bardziej aktualny i wyższej jakości. Dzięki temu prostsze są prace badawcze: eksploracja zasoby oraz jego ponowne wykorzystanie. Jednocześnie wciąż nie udało się (stan na rok 2023) rozwiązań problemu braku komunikacji bezpośredniej (interoperacyjności) między systemem edycji danych a systemej ich prezentacji pbl.ibl.waw.pl (rekordy muszą być okresowo importowane po ich – automatycznej – konwersji).
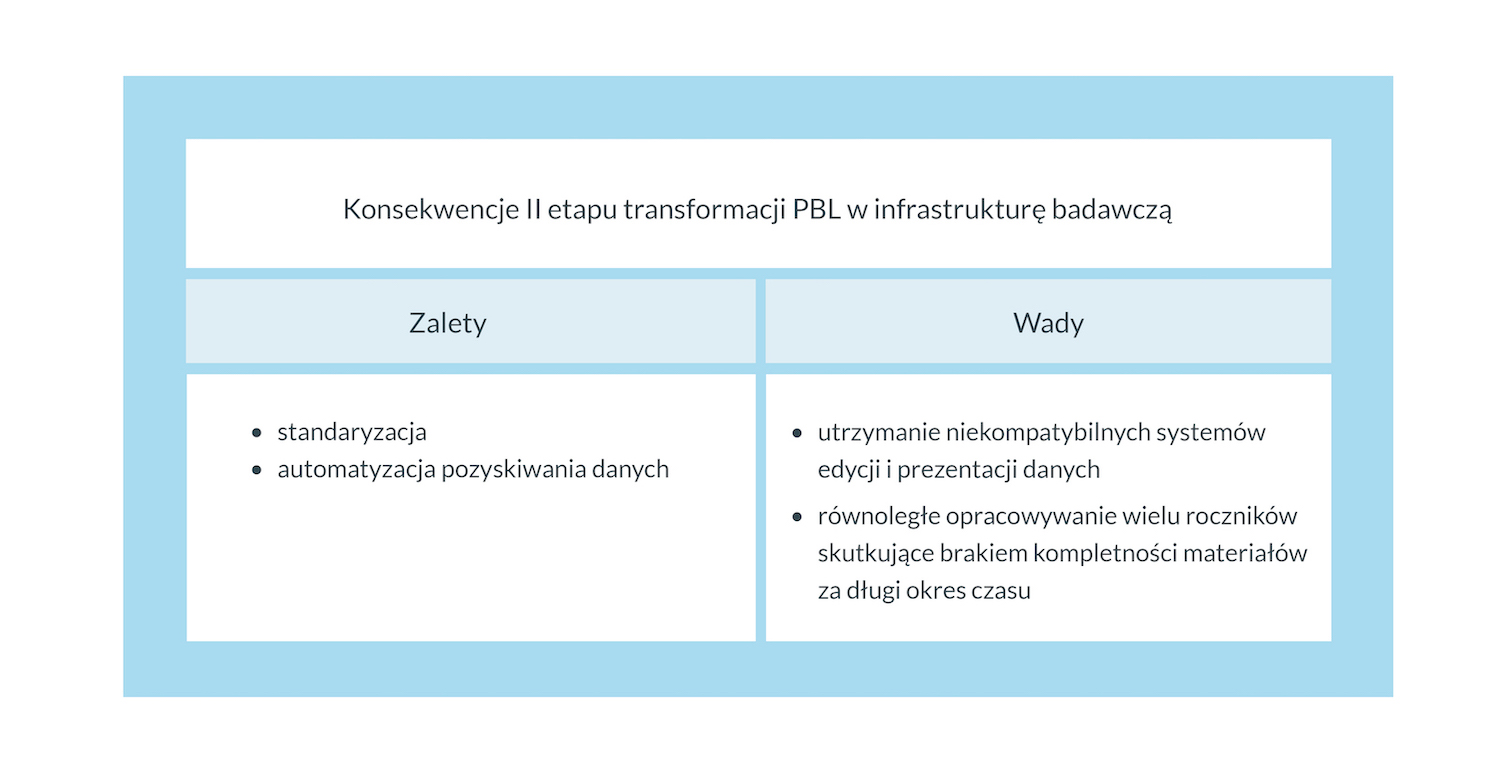
Tab. 3 Konsekwencje II etapu transformacji PBL w infrastrukturę badawczą, źródło: oprac. własne