
Tworzenie korpusów
Pierwszym etapem analizy jest stworzenie korpusu językowego lub korpusu tekstowego. Jest to pojęcie z zakresu językoznawstwa korpusowego. Najprościej mówiąc, korpus tekstowy jest po prostu zbiorem tekstów spełniających określone kryteria (Lewandowska-Tomaszczyk 2005). Zależnie od potrzeb i zainteresowań badaczy, tworzone są bardzo różne korpusy: zaczynając od korpusów prezentujących stan języka w określonym momencie historycznym, przez korpusy tekstów reprezentujących jeden gatunek (np. tekstów prasowych, tekstów przemówień sejmowych, powieści), czy dany typ nadawcy (np. korpusy tekstów tworzonych przez kobiety, korpusy tekstów osób cierpiących na określone schorzenia). Powstają też korpusy poszczególnych języków naturalnych, w tym Narodowy Korpus Języka Polskiego (nkjp.pl; NKJP).
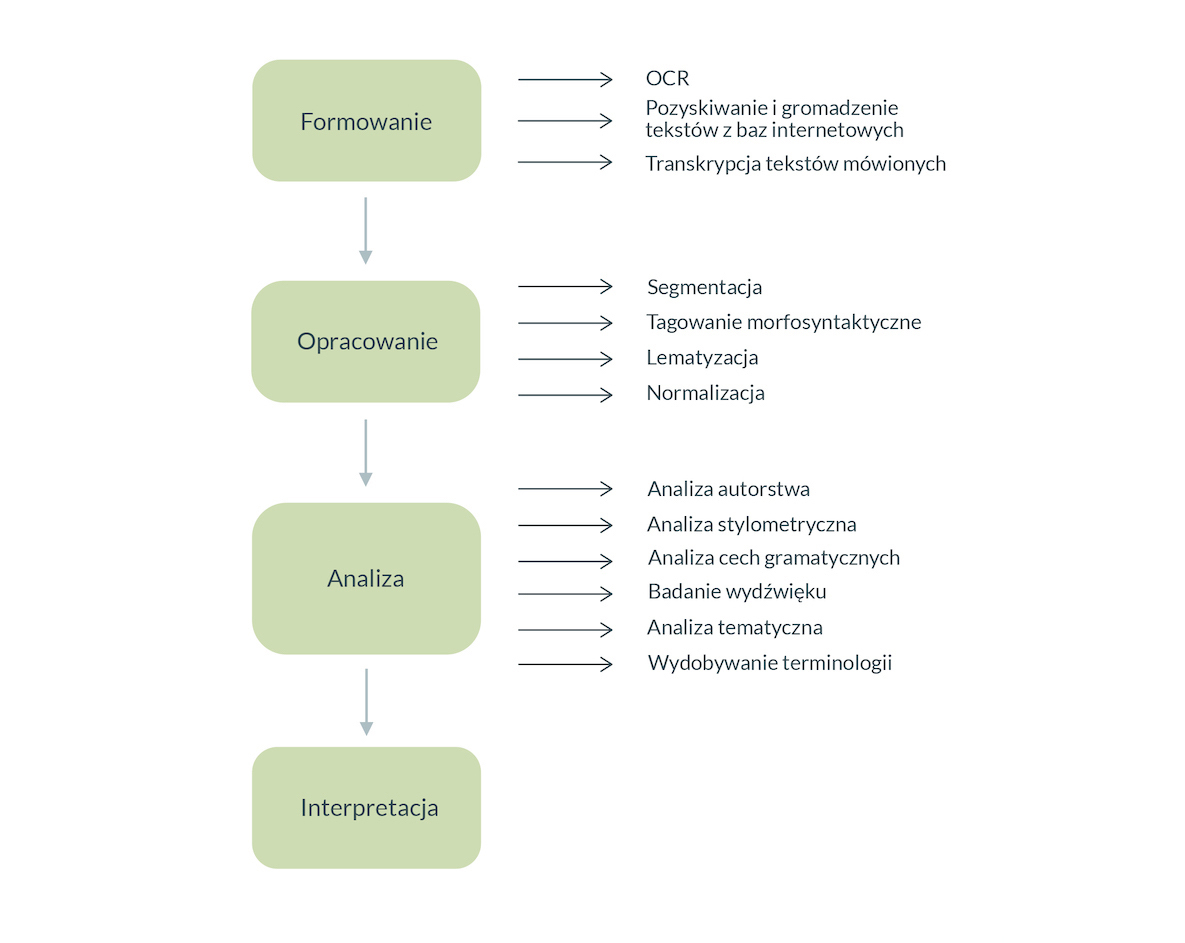
Il. 8 Etapy opracowania tekstu, źródło: oprac. własne
W ramach korpusu wydzielone mogą zostać podkorpusy – na przykład, korpus dzieł jednego autora można więc podzielić na podkorpusy zawierające teksty określonego rodzaju lub gatunku, ale można też wydzielić podkorpusy dla określonego okresu czy na innej podstawie, np. ze względu na obecność czy natężenie cechy, którą badamy.
Dostępne narzędzia
Na etapie formowania możliwa jest np. automatyczna transkrypcja tekstu mówionego do formy pisemnej czy jego wstępne oczyszczenie z elementów takich jak literówki i podstawowe błędy ortograficzne (do tego można wykorzystać np. narzędzie Speller) czy interpunkcyjne (np. Punctuator).
Spośród narzędzi wykorzystanych w fazie formowania warto zwrócić szczególną uwagę na narzędzia służące do tworzenia korpusów. Infrastruktura CLARIN-PL udostępnia w tym zakresie przede wszystkim Korpusomat, KonText oraz Inforex. Wszystkie te serwisy pozwalają użytkownikowi na stworzenie i przechowywanie korpusów tekstów, wszystkie dysponują wbudowanymi funkcjami wspierającymi także dalsze działania ze zgromadzonym materiałem, jednak każde z nich najlepiej sprawdzi się w nieco innych sytuacjach. Korpusomat (Kieraś, Kobyliński, i Ogrodniczuk 2018) pozwala na samodzielne tworzenie korpusów tekstowych, automatycznie anotowanych w warstwie morfosyntaktycznej. Służy przede wszystkim do uzyskiwania uproszczonych statystyk z pojedynczego korpusu, jednak zawiera też moduł umożliwiający porównanie dwóch korpusów pod kątem cech gramatycznych i leksykalnych. Wynik przedstawiany jest w formie listy cech, czyli zdefiniowanych cech gramatycznych i leksykalnych, których występowanie w obu korpusach zostaje przeliczone na tzw. wskaźnik istotności cechy i następnie porównane. Uzyskane w ten sposób statystyki mogą być mniej czytelne dla badacza niewprawnego w rozszyfrowywaniu określeń typowych dla języka NLP, ale są precyzyjne i potrafią dać nowe spojrzenie na analizowany temat.
Inforex (Marcińczuk i Oleksy 2019) to rozbudowany system pozwalający na tworzenie, przechowywanie i przetwarzanie korpusów tekstowych. Umożliwia on nanoszenie anotacji – ręczne i automatyczne – a także operacje na wprowadzonym do niego korpusie, takie jak tworzenie list frekwencyjnych, statystyki i dystrybucje wyrazów i tagów czy wydobywanie statystyk dotyczących anotacji. Interesującą funkcją jest możliwość nanoszenia i uzgadniania anotacji przez kilku anotatorów. System pozwala też na zaawansowaną tokenizację i tagowanie tekstów z ręczną korektą przez badacza. Ponieważ w ramach opracowywania korpusu Inforex umożliwia też tokenizację, lematyzację i tagowanie tekstu, możliwe jest wykorzystanie go także do tworzenia list frekwencyjnych i wydobywania statystyk dotyczących tekstu. Jest to bardzo wszechstronne narzędzie, które może być wykorzystywane do większości podstawowych operacji na korpusie tekstowym.
Ostatnim omawianym narzędziem, umożliwiającym tworzenie korpusów, jest KonText. Jego głównym zadaniem jest porównywanie dwóch korpusów, w tym korpusów w dwóch różnych językach. Dodatkowym atutem tego narzędzia jest rozbudowana wyszukiwarka, pozwalająca nie tylko na prześledzenie występowania określonego słowa i odnajdywania kolokacji i konkordancji, lecz także budowanie zaawansowanych zapytań i uzyskiwanie statystyk dotyczących występowania słownictwa i form gramatycznych w poszczególnych podkorpusach. Jest to narzędzie bardzo wygodne w użyciu i dające przejrzyste wyniki.
Gdy mowa o funkcji porównania korpusów, warto wspomnieć też o serwisie CompCorp (Walkowiak 2017), który powstał specjalnie w celu porównywania między sobą dwóch korpusów. To narzędzie pozwala na porównanie zasobu leksykalnego (m.in. odnajdując słowa najbardziej różnicujące dwa zbiory tekstów), charakterystyki gramatycznej i innych cech, takich jak długość zdań.