
Zastosowane rozwiązania
Ostatecznie dla elektronicznej wersji Słownika polszczyzny XVI wieku został opracowany prostszy i bardziej elastyczny w stosunku do proponowanego przez Szafrana formalizm (DTD zawiera tylko 57 elementów), który został użyty do testowego otagowania materiału XXXV tomu Słownika, a którego podstawowymi założeniami są łatwość znakowania i czytelna prezentacja danych w internecie. Z uwagi na potrzebę jak najprostszego opisu pełnej struktury artykułu hasłowego nie zdecydowano się jednak na zastosowanie zaleceń TEI. Poszczególne elementy główne odzwierciedlają zasadniczy podział na rubryki i w razie potrzeby mogą występować fakultatywnie, natomiast grupy znaczeniowe, zawierające wszystkie potencjalne rubryki wewnętrzne, mogą być zagnieżdżane w sobie rekursywnie, co zapewnia zdolność tworzenia nawet bardzo skomplikowanych schematów znaczeniowych dla hasła przy jednocześnie dość prostym DTD. Dodatkowym atutem tego formalizmu jest możliwość etapowego (od ogółu do szczegółu) prowadzenia prac digitalizacyjnych.
W ramach realizacji projektu słownikowego w latach 2013-2018 rozwijano specjalny edytor, który powstał wcześniej dla prób zastosowania schematu Szafrana. Zaimplementowano w nim nowy, uproszczony formalizm oraz dopracowano interfejs użytkownika, który miał pozwalać na wygodne wprowadzanie oraz tagowanie istniejących i nowych haseł. Było to o tyle ważne, że do wykonania digitalizacji poza redaktorami haseł Słownika zatrudniono także osoby spoza pracowni, które po przeszkoleniu były w stanie prawidłowo identyfikować i oznaczać poszczególne elementy artykułów hasłowych.
Ponieważ digitalizacja Słownika nie należy do zadań statutowych IBL realizowanych w pracowni, prace postępowały stopniowo w zależności od pozyskiwanych dodatkowych środków finansowych. W latach 2014–2018 przeprowadzono retrodigitalizację haseł z zakresu A – NIĆ, w roku 2020 rozpoczęto realizację projektu obejmującego m.in. dokończenie retrodigitalizacji haseł z zakresu NIE – P’ (w toku). Równolegle prowadzona jest digitalizacja bieżąca (zakres R – S). W wyniku retrodigitalizacji oraz digitalizacji bieżącej w elektronicznej wersji Słownika znajduje się obecnie ponad 54,5 tys. artykułów hasłowych.
Słownikowa część serwis internetowego spxvi.edu.pl opiera się na trzech zasadniczych elementach, którymi są indeks haseł, artykuły hasłowe zdeponowane w bazie danych w formacie XML oraz zarządzająca tym aplikacja internetowa.
Il. 6. Rozwój wersji elektronicznej Słownika polszczyzny XVI wieku, źródło: oprac. własne.
Indeks
Porządkującą rolę w systemie elektronicznego słownika odgrywa indeks haseł umieszczony w oddzielnej tabeli bazy danych (MySQL). Każde hasło jest osobnym rekordem w tabeli, co wymusiło pewne uproszczenia i optymalizacje w systemie haseł i odsyłaczy. Obecnie system ten liczy sześć formalnych typów haseł. Aplikacja zarządzająca indeksem dokonuje sprawdzenia bazy danych z artykułami hasłowymi i generuje linki do istniejących w bazie artykułów.
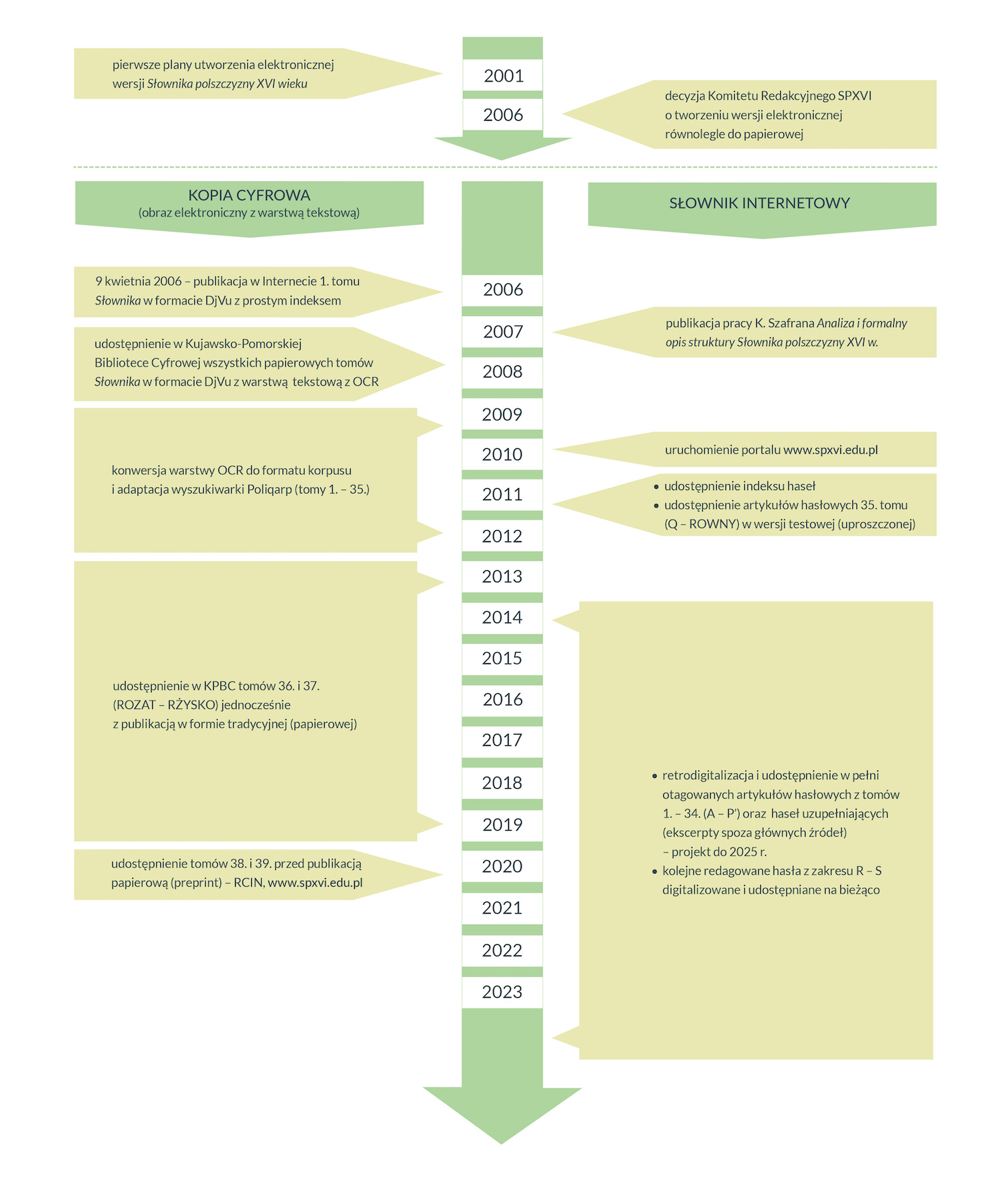
Il. 7. Przykład wyniku wyszukiwania haseł w indeksie wersji elektronicznej Słownika, źródło: spxvi.edu.pl
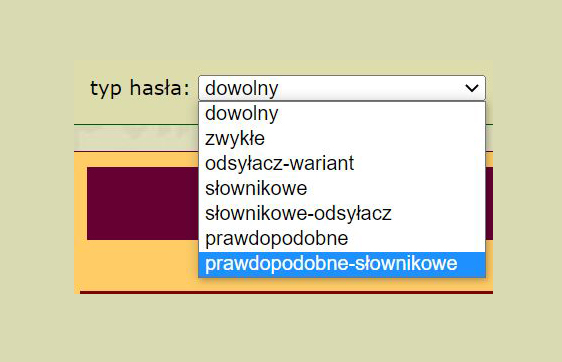
Indeks wyposażony jest w prostą wyszukiwarkę haseł pozwalającą na wyszukanie w bazie zadanego ciągu znakowego. Można przy tym określić jedną z trzech pozycji tego ciągu w szukanych hasłach – na początku, w środku i na końcu wyrazu.
Il. 8. Opcje filtrowania wyników wyszukiwania haseł w indeksie, źródło: spxvi.edu.pl
Ponadto możliwe jest zawężenie przeszukiwanego zbioru do jednego typu haseł – hasła zwykłe, warianty/odsyłacze, hasła słownikowe, odsyłacze słownikowe, hasła prawdopodobne i hasła prawdopodobne słownikowe. Wyniki kwerendy można wyświetlić w porządku a fronte oraz a tergo. Obecnie aplikacja internetowa wyświetla listę haseł z podaną informacją o typie hasła, jego kanoniczności, czyli pochodzeniu materiału z kanonu źródeł, dla którego podawana jest statystyka. Ponadto wygenerowana lista zawiera informacje o istnieniu wątpliwości co do formy podstawowej, dla haseł tzw. kanonicznych podawana jest frekwencja (dla haseł spoza kanonu źródeł podano frekwencję „0”), zweryfikowane hasła zwykłe wyposażone są w dane o kategorii gramatycznej, zaś kolumna „uwagi” może zawierać różne dane, przede wszystkim warianty hasła, odsyłacze do hasła głównego czy proweniencję haseł słownikowych. Dla haseł, które nie zostały jeszcze zredagowane bądź zdigitalizowane, aplikacja tworzy krótką informację pobierając dane (m.in. o frekwencji) z tabeli indeksu.

Il. 9. Informacja o braku artykułu hasłowego dla szukanego hasła, źródło: spxvi.edu.pl
Baza artykułów hasłowych
Tekst artykułu hasłowego ma format XML, a jego walidację zapewnia specjalny edytor, który pozwala zarówno tworzyć nowe artykuły hasłowe, jak i digitalizować teksty pozyskane przez skanowanie i OCR wydanych drukiem tomów lub przez konwersję plików poligraficznych. Gotowy plik z artykułem hasłowym trafia jako kolejny rekord do bazy danych. Zasadnicze prace digitalizacyjne skupiają się jednak na wypełnianiu danymi bazy artykułów hasłowych. Początkowo na materiale tomu XXXV próbnie wykonano konwersję z formatu poligraficznego programu Kombi, który od 2003 roku służy w pracowni do przygotowania składu drukarskiego kolejnych tomów słownika. Ze względu na specyfikę formatu plików programu Kombi zachodzi konieczność konwersji pośredniej na format RTF (Rich Text Format). Kombi pozwala bez trudu zapisać pliki w formacie RTF. Pliki pośrednie z kolei łatwo dają się otwierać w edytorze haseł przygotowanym przez współpracującego z pracownią informatyka. W edytorze haseł plik podlega znakowaniu tagami XML, przy czym użytkownik nie ma kontaktu z surową strukturą pliku w formacie XML, lecz widzi tylko graficzną reprezentację znaczników w postaci ramek. Ułatwia to śledzenie struktury hasła, zwłaszcza zagnieżdżenia poszczególnych grup i rubryk artykułu hasłowego. Po imporcie do edytora tekst artykułu hasłowego automatycznie opatrywany jest głównym elementem, którego atrybuty nadpisują dane hasła znajdujące się w indeksie, jednocześnie każda ich zmiana powoduje aktualizację danych w indeksie, co zapewnia spójność danych w systemie. Artykuły hasłowe za pomocą systemu linków pozwalają na budowanie sieci połączeń między hasłami.
Aplikacja
Wszystkie dane gromadzone są w relacyjnej bazie danych, którą zarządza aplikacja internetowa napisana w języku Python i działająca pod kontrolą frameworku Django. Dzięki szablonom XSLT (eXtensible Stylesheet Language Transformations) i XSL-FO (eXtensible Stylesheet Language Formatting Objects) możliwa jest prezentacja wybranego hasła na stronie internetowej oraz wygenerowanie pliku PDF (Portable Document Format) zawierającego dane hasło w postaci zbliżonej do wersji drukowanej Słownika. Otagowane artykuły hasłowe umożliwiają aplikacji wyświetlanie danych w specjalny sposób. Domyślne jest np. formatowanie tabeli z paradygmatem form fleksyjnych dla leksemów odmiennych, a także generowanie spisu treści ukazującego strukturę znaczeniową hasła i jednocześnie stanowiącego system linków do poszczególnych znaczeń, co ułatwia korzystanie z dużych haseł i jednocześnie jest spełnieniem postulatów Z. Saloniego dotyczących niezbyt przejrzystych graficznie artykułów hasłowych w wersji drukowanej słownika (Saloni 2009, s. 358).