
Zastosowane rozwiązania
Istniejący obecnie zalążek korpusu liczy 135 tys. segmentów. Zdeponowano je w bazie danych, a poszczególne rekordy zostały wygenerowane na bazie plików XML utworzonych w specjalnym edytorze pozwalającym na ręczną segmentację i lematyzację tekstu oraz tagowanie poszczególnych segmentów znacznikami fleksyjnymi. W procesie segmentacji i tagowania wykorzystano stworzony specjalnie na potrzeby digitalizacji słownika i bazy tekstów edytor XML, w którym dodatkowy moduł oprócz możliwości ręcznego podziału tekstu na segmenty pozwala na przypisanie poszczególnym segmentom trzech podstawowych wartości: identyfikatora wyrazu hasłowego (lematu) w indeksie słownika, odczytanej postaci segmentu w tekście oraz jego formy gramatycznej. Zalążek korpusu zaopatrzony jest w prostą wyszukiwarkę, która pozwala na odnalezienie szukanego segmentu lub jego fragmentu (np. określonego prefiksu bądź sufiksu). Wyniki wyszukiwania wyświetlane są w zależności od ustawień użytkownika jako tekst transliterowany lub transkrybowany, przy czym każdy wyszukany segment zaopatrzony jest w kontekst ustalony na 5 segmentów przed i po. Przy wynikach wyświetlane są również pozostałe dane: kategorie gramatyczne, znaczniki fleksyjne, lokalizacja w tekście oraz forma podstawowa, przy czym na bazie lokalizacji i formy tworzone są linki odsyłające odpowiednio do określonego miejsca w całym tekście lub do hasła w słowniku elektronicznym.
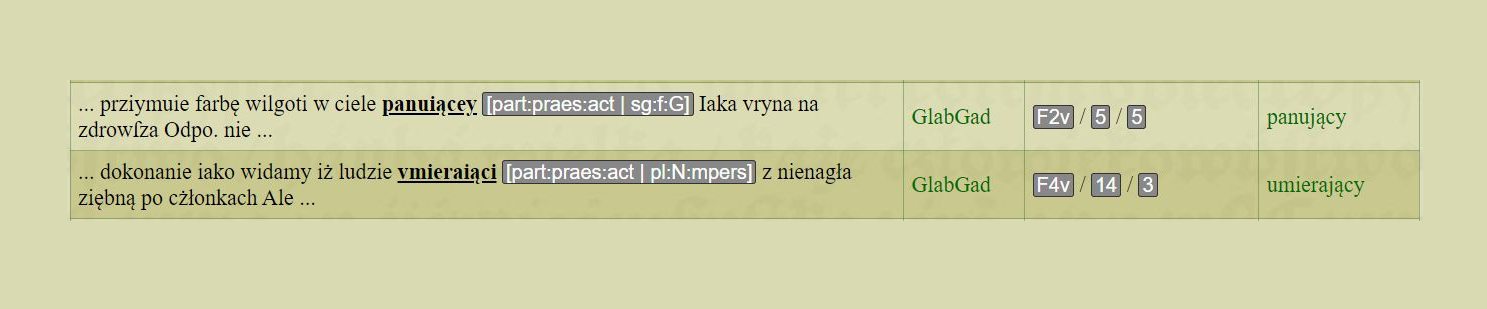
Il. 10. Przykład wyniku wyszukiwania w korpusie, źródło: spxvi.edu.pl