
Infrastruktura cyfrowa dla literaturoznawstwa w ramach projektu Dariah.lab
Model cyfryzacji procesu badawczego został wykorzystany w pracach IBL PAN w ramach projektu Dariah.lab, którego zadaniem było stworzenie solidnych podstaw infrastrukturalnych literaturoznawczej infrastruktury badawczej. Celem prac było rozpoznanie cyfrowych potrzeb badawczych w tej dyscyplinie i odpowiedź na nie, polegająca na zbudowaniu specjalistycznych usług wspierających kolejne etapy procesu badawczego.
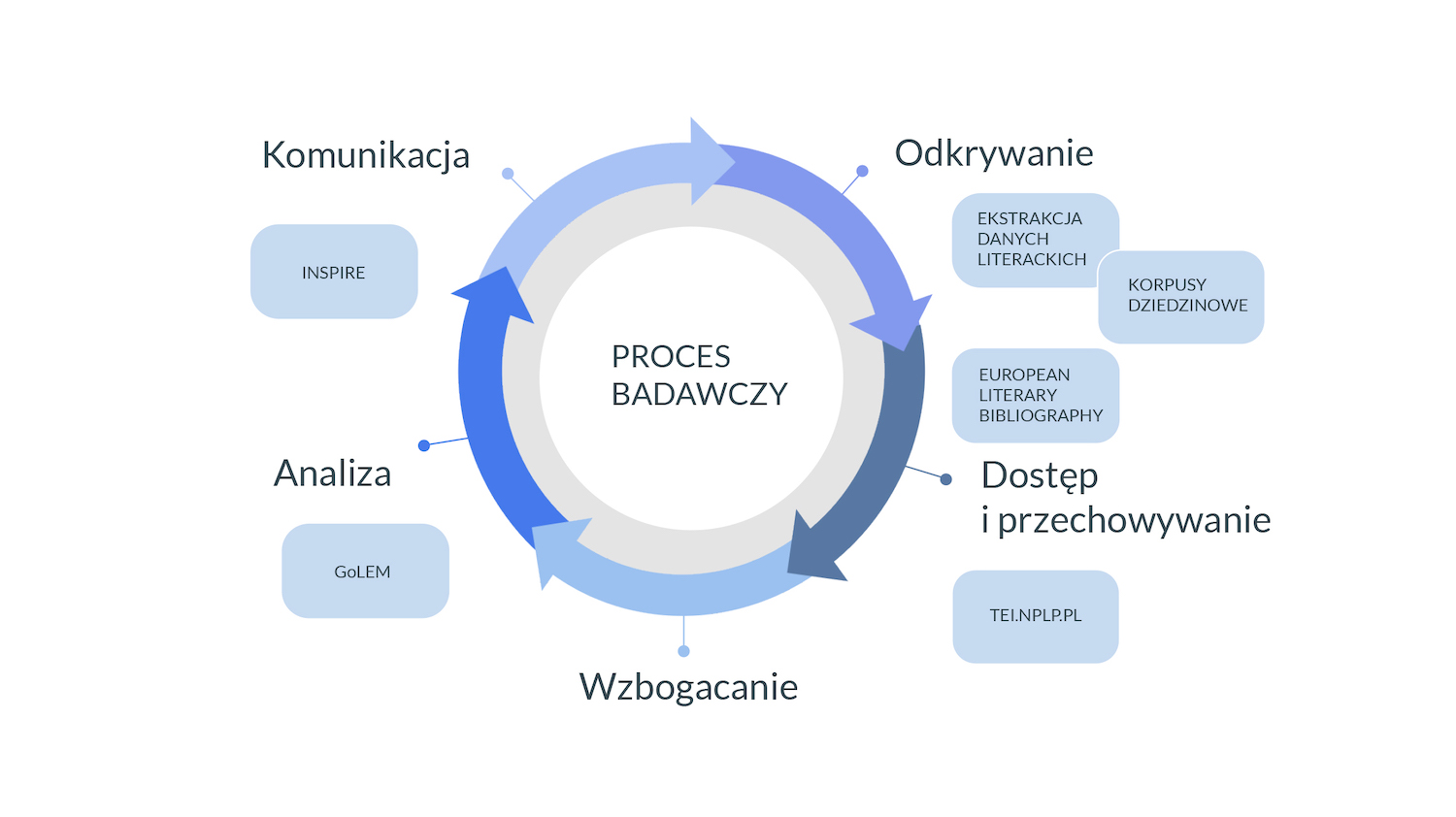
Il. 8 Proces badawczy, oprac. własne
Kluczowym wyzwaniem w cyfrowych badaniach literaturoznawczych jest dostępność jakościowych korpusów dokumentów. Aby skutecznie odkrywać istotne dla badań dokumenty i budować z nich korpusy, w projekcie Dariah.lab zainicjowano pracę nad Korpusem Dyskursu Literaturoznawczego (KDL), który obejmie polskie prace z zakresu badań literackich z lat 1822–2022. Twórcy korpusu wychodzą z założenia iż okres dwustu lat pozwoli zarówno zgromadzić reprezentatywny materiał, jak i uchwycić różne rodzaje przemian w ramach dyscypliny Taki korpus służyć może badaczom i badaczkom do lepszego rozumienia procesów literackich i literaturoznawczych, jak pojawianie się kluczowych pojęć i przemiany ich znaczenia, sposób interpretowania konkretnych tekstów czy pisania o konkretnych twórcach. Wykorzystujemy go też jako podstawę materiałową do działań analitycznych w opisywanym niżej narzędziu GoLEM.
W badaniach literackich często pełne wersje tekstów nie są dostępne, w związku z czym kluczowe jest identyfikowanie, gromadzenie i przechowywanie samych informacji o tych dokumentach czyli metadanych. Dzięki takim zbiorom, mimo braku dostępu do pełnych wersji tekstów, badać można wiele aspektów kultury literackiej, w tym sieci relacji między jej aktorami (autorami, tłumaczami i innymi postaciami kultury), popularność gatunków literackich czy aktywność wydawnictw. W ramach Dariah.lab zmodernizowano narzędzie do gromadzenia i wzbogacania danych bibliograficznych służące projektowi European Literary Bibliography. ELB to inicjatywa agregacji specjalistycznych metadanych literaturoznawczych i literackich z baz europejskich (w szczególności bibliografii dziedzinowych i narodowych), obejmująca obecnie zasoby polskie, czeskie, fińskie i hiszpańskie. Modernizacja narzędzia pozwoliła na bardziej wydajne przetwarzanie danych oraz wzbogacanie metadanych poprzez implementację modeli Linked Open Data (np. nadawanie trwałych identyfikatorów osobom, instytucjom, konceptom), bazujące na zasobach Wikidata. W efekcie następuje harmonizacja heterogenicznych zasobów danych i możliwa jest eksploracja powiązań między kulturami literackimi wielu krajów. Daje to solidne podstawy do rozwoju badań komparatystycznych, europeistyki literackiej czy literatury światowej. ELB wspiera odkrywanie treści potrzebnych do tych badań.
Wzbogacanie danych literaturoznawczych, jak wspominaliśmy wyżej, może być przeprowadzone automatycznie lub ręcznie. W ramach DARIAH.lab powstaje infrastruktura wspomagająca obydwa procesy: anotator jednostek literaturoznawczych oraz specjalistyczną platformę do tworzenia edycji cyfrowych.
Anotator terminów literackich zbudowano na podstawie danych ze specjalistycznych źródeł literaturoznawczych słowników, encyklopedii, katalogów, kartotek. Na bazie tych materiałów powstał zestaw słowników terminów i bytów literackich (osób, czasopism, grup literackich, utworów, wydarzeń, nagród, instytucji, miejsca akcji, związanych z literaturą). Zestaw słowników pozwala na zautomatyzowaną eksplorację i anotację tekstów – oznaczanie w nich jednostek informacji istotnych dla badań literaturoznawczych. Środowisko badawcze może wykorzystać takie zasobu do tworzenia własnych narzędzi analitycznych (zob. GoLEM poniżej), anotacji korpusów tekstowych, dostrajania narzędzi do automatycznej ekstrakcji informacji (np. ekstrakcji słów kluczowych czy modelowania tematycznego) w taki sposób, by odpowiadały potrzebom literaturoznawców lub tworzenia i wzbogacania kolejnych słowników czy baz wiedzy.
Do przygotowania i anotowania tekstu służy także TEI.NPLP.PL, specjalistyczna platforma do tworzenia naukowych edycji cyfrowych . Umożliwia pracę z tekstem i anotowanie go dowolnymi znacznikami, zależnymi od metodologii i celów projektu badawczego. Mogą to być zatem np. osoby, miejsca i organizacje, jak i opisy metatekstowe (np. rozdział, wers, strona) czy kolacjonowanie różnych wariantów tekstu. TEI.NPLP.PL do anotacji wykorzystuje międzynarodowy standard TEI (Text Encoding Initiative), co zapewnia interopreacyjność tekstów z innymi projektami i możliwość wykorzystania ich na kolejnych etapach procesu badawczego – zarówno do publikacji edycji, jak i do analizy tekstowej (np. zbadanie relacji między oznaczonymi bytami).
Poprzez narzędzia służące analizie rozumiemy oprogramowanie pozwalające na eksplorację korpusów tekstów poprzez modelowanie tematyczne, ekstrakcję terminologii i bytów literackich i literaturoznawczych (por. wyżej), wizualizację geoprzestrzenną oraz porównanie znaczeniowe terminologii występującej w różnych tekstach. Grafowy Literacki Eksplorator Maszynowy (GoLEM) to system do zaawansowanej analizy i wizualizacji powiązań między terminami, bytami i słowozbiorami (topikami) w tekstach naukowych, przede wszystkim w tekstach z zakresu literaturoznawstwa, w wymiarze synchronicznym i diachronicznym. Dzięki GoLEMowi badacze i badaczki literatury bez konieczności prac programistycznych mogą prowadzić badania oparte na danych, w szczególności przy wykorzystaniu takich metod, jak analiza sieciowa (network analysis). GoLEM ma trzy komponenty: analiza bytów (rozpoznawanie bytów i częstości ich występowania z uwzględnieniem zmian w czasie), analiza terminów i pojęć ( rozpoznawanie terminów literackich i literaturoznawczych, ich kontekstu znaczeniowego i zmian w czasie), analiza słowozbiorów (częściowo nadzorowane modelowanie tematyczne korpusów). GoLEM rozwijany jest obecnie na tekstach z KDL ale docelowo będzie wspomagać wieloaspektowe badania literaturoznawcze na różnych tekstach.
W końcu w ramach wsparcia możliwości upowszechniania wyników badań i współpracy społeczności literaturoznawczej w szerszym kontekście humanistyki cyfrowej powstała platforma Inspire. Jest to platforma umożliwiająca wymianę wiedzy oraz danych między instytucjami z zakresu badań o kulturze i ich odbiorcami. Platforma popularyzuje humanistykę cyfrową poprzez teksty informacyjne, artykuły, filmy i podcasty o nauce i kulturze.